Data Parallelism in Distributed Training - Python Automation and Machine Learning for ICs - - An Online Book - |
||||||||
| Python Automation and Machine Learning for ICs http://www.globalsino.com/ICs/ | ||||||||
| Chapter/Index: Introduction | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | Appendix | ||||||||
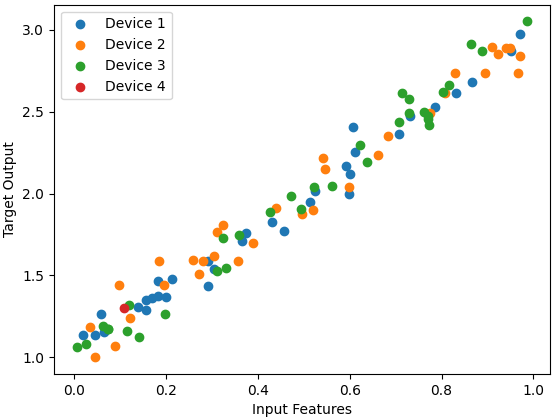
================================================================================= Data parallelism in distributed training refers to running the same model and computation on every device but training each device with a different subset of the training samples. This scripts used for Figure 3754a generate random training samples and splits them into different subsets for each device.
(a)
(b)
(c)
(d)
(e) Figure 3754a. Data parallelism in distributed training: (a) Code, (b) Code, (c) Code, (d) Code, and (e) Code. ============================================
|
||||||||
| ================================================================================= | ||||||||
|
|
||||||||