=================================================================================
Bayesian methods are a statistical approach used in various fields, including machine learning, to make predictions or inferences based on probability theory and prior knowledge. In Bayesian machine learning, the key idea is to update your beliefs (represented as probability distributions) as new data becomes available. This is in contrast to some other machine learning techniques, such as frequentist methods, where parameters are treated as fixed, unknown values.
The key concepts related to Bayesian machine learning are::
The concept of a "distribution over a distribution" is central to Bayesian probability and Bayesian statistics. In Bayesian inference, you often deal with probability distributions over parameters or hypotheses, and these probability distributions are themselves characterized by parameters. This creates a hierarchical or nested structure of distributions, where you have a distribution over another distribution.
-
Bayes' Theorem: This is the fundamental principle underlying Bayesian methods. It describes how to update the probability of a hypothesis (or model) given new evidence.
-
Prior and Posterior Distributions: In Bayesian inference, you start with a prior probability distribution that represents your initial beliefs about a parameter or hypothesis. As you observe new data, you update this distribution to get the posterior distribution, which reflects your beliefs after considering the data.
-
Updating with Data (Likelihood): When you observe new data, you use a likelihood function. The likelihood represents how likely the data is under different values of the parameter. It's a conditional distribution that describes the probability of the observed data given the parameter.
-
Distribution Over Parameters Given Data (Posterior): The key step in Bayesian inference is to update your prior distribution based on the observed data. This update is performed using Bayes' Theorem, which results in a posterior distribution. The posterior distribution represents your updated beliefs about the parameter given the new data. It's a distribution over the parameter space and is the distribution over a distribution.
-
Distribution Over Parameters (Prior): In Bayesian statistics, you start with a prior probability distribution that represents your beliefs or uncertainty about a parameter or hypothesis. This prior distribution is a distribution over the possible values of that parameter. For example, if you're estimating the mean of a population, you might have a prior distribution for that mean.
-
Bayesian Inference: This is the process of using Bayes' Theorem to update your beliefs and make predictions. It involves calculating the posterior distribution and using it to make inferences.
-
Bayesian Networks: These are graphical models that represent probabilistic relationships between variables. They are commonly used in probabilistic graphical models and can be used for various machine learning tasks.
-
Bayesian Optimization: This is a technique used for hyperparameter tuning and optimizing functions that are expensive to evaluate. It uses Bayesian inference to build a probabilistic model of the objective function and guides the search for the best parameters.
-
Bayesian Deep Learning: In the context of neural networks, Bayesian deep learning aims to model uncertainty in the network's predictions by using Bayesian methods. This can help in tasks like uncertainty estimation and robustness.
Bayesian inference, Bayesian probability, and Bayesian statistics are related concepts, but they refer to different aspects of the broader Bayesian framework in statistics and probability theory.
Table 3861. Comparison between Bayesian probability, Bayesian statistics and Bayesian inference.
| |
Bayesian Probability |
Bayesian Statistics |
Bayesian Inference |
| Concept |
- Bayesian probability is a fundamental concept in probability theory. It represents a measure of uncertainty or belief in the likelihood of an event occurring.
- Bayesian probability is based on Bayes' theorem, which is a mathematical formula that describes how to update prior beliefs (prior probabilities) in light of new evidence to obtain posterior probabilities.
- It is a general framework for updating probabilities based on new information and can be used in various contexts, not just statistics. It is a fundamental concept that underlies Bayesian statistics and Bayesian inference.
|
- Bayesian statistics is a branch of statistics that uses Bayesian probability theory to perform statistical analysis. It provides a framework for making inferences and decisions about unknown parameters or hypotheses.
- In Bayesian statistics, probability distributions are assigned to parameters or hypotheses, and the uncertainty about these parameters is expressed through probability distributions.
- It combines prior beliefs (prior probabilities) with observed data to obtain posterior probabilities, allowing for the estimation of parameters and the quantification of uncertainty.
|
- Bayesian inference is a specific application of Bayesian statistics, which involves the process of making predictions, estimating parameters, and testing hypotheses in a Bayesian framework.
- In Bayesian inference, you start with prior beliefs (prior probabilities), collect new data, and update your beliefs to obtain posterior probabilities. This process is often used for parameter estimation, hypothesis testing, and predictive modeling.
- Bayesian inference is widely used in various fields, including machine learning, data analysis, and scientific research, to make informed decisions and draw conclusions from data.
|
| Equations |
Bayes' Theorem: This is the fundamental equation in Bayesian probability. P(A|B) = [P(B|A) * P(A)]/P(B) Where:
- P(A|B) is the posterior probability of event A given evidence B.
- P(B|A) is the probability of observing evidence B given event A.
- P(A) is the prior probability of event A.
- P(B) is the probability of observing evidence B.
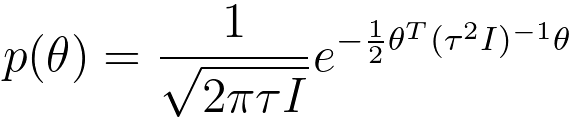 |
Bayesian Inference: In Bayesian statistics, the key equation is the posterior distribution, which represents the updated probability distribution of parameters or hypotheses based on observed data. P(θ|D) ∝ P(D|θ) * P(θ) Where:
- P(θ|D) is the posterior distribution of the parameter θ given data D.
- P(D|θ) is the likelihood of observing data D given parameter θ.
- P(θ) is the prior distribution of the parameter θ.
- ∝ denotes proportionality, indicating that the right-hand side is proportional to the left-hand side.
|
-
Parameter Estimation: In the context of Bayesian inference, if you want to estimate a parameter θ based on data D, the key equation is the posterior distribution for θ: P(θ|D) ∝ P(D|θ) * P(θ) This equation is used to compute the posterior distribution for θ after observing data D.
-
Hypothesis Testing: In Bayesian hypothesis testing, the key equation relates the posterior odds ratio to the likelihood ratio and prior odds: Posterior Odds = Prior Odds × Likelihood Ratio O(Prior) = O(Posterior) × LR Where:
- O(Prior) is the prior odds of the hypothesis.
- O(Posterior) is the posterior odds of the hypothesis.
- LR is the likelihood ratio.
|
|