Gradient Descent and its Algorithm (for Updating θ) - Python for Integrated Circuits - - An Online Book - |
||||||||
| Python for Integrated Circuits http://www.globalsino.com/ICs/ | ||||||||
| Chapter/Index: Introduction | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | Appendix | ||||||||
================================================================================= Gradient descent is not an algorithm for learning a specific model but rather an optimization technique used to train a wide range of machine learning models, including neural networks, support vector machines, and linear regression. It's essential for updating model parameters to minimize a loss function, making it a crucial component of many learning algorithms. When you have multiple training samples (also known as a dataset with multiple data points), the equations for the hypothesis and the cost function change to accommodate the entire dataset. This is often referred to as "batch" gradient descent, where you update the model parameters using the average of the gradients computed across all training samples. Hypothesis (for multiple training samples): The hypothesis for linear regression with multiple training samples is represented as a matrix multiplication. Let be the number of training samples, be the number of features, be the feature matrix, and be the target values. The hypothesis can be expressed as: where,
Cost Function (for multiple training samples): The cost function in linear regression is typically represented using the mean squared error (MSE) for multiple training samples. The cost function is defined as: where,
Equation 3974b gives you to train the entire set m, so sometimes this type of gradient descent has another name, which is batch gradient descent. The key difference between SGD and batch Gradient Descent is that SGD updates the parameters more frequently and with noisier estimates of the gradient, which can lead to faster convergence and better generalization, especially when dealing with large datasets. However, it can also introduce more variance in the optimization process due to the random sampling of training examples. Gradient Descent (for updating ): To train the linear regression model, you typically use gradient descent to minimize the cost function. The update rule for in each iteration of gradient descent is as follows: where,
It also can be given by, where,
Then, we have: In each iteration, each parameter is updated simultaneously using the gradients calculated over the entire training dataset. This process is repeated until the cost function converges to a minimum. This batch gradient descent process allows you to find the optimal parameters that minimize the cost function, making your linear regression model fit the training data as closely as possible. By combining Equations 3974d and 3974g, then we can have, With multiple training examples, we then have, where, i - The ith training example. This descent process described in Equation 3974i will repeat until convergence. Similar to many other optimization algorithms, the gradient descent involves iteratively updating model parameters to minimize a cost function. The process continues until a convergence criterion is met. Convergence here means that the algorithm has reached a point where further iterations do not significantly improve the cost function or model performance. This is a common termination condition in many machine learning algorithms. When we define the cost function J(θ) for linear regression as the mean squared error (MSE), it turns out to be a quadratic function of the parameters θ. This can be proved as shown below. In linear regression, the hypothesis function hθ(x) is defined as the linear combination of features and parameters: Where:
The mean squared error (MSE) cost function J(θ) is defined as: Where:
Now, let's expand the MSE cost function: each term inside the summation is a linear combination of the parameters θ₀, θ₁, θ₂, ..., θ_n and the input features x₁, x₂, ..., x_n. When you expand and simplify the squared terms within the summation, you get a polynomial of degree 2 (quadratic) with respect to the parameters θ₀, θ₁, θ₂, ..., θn. The presence of squared terms makes it a quadratic function. The goal of linear regression is to find the values of θ₀, θ₁, θ₂, ..., θn that minimize this quadratic cost function J(θ), and that's typically done using optimization techniques like gradient descent. Therefore, for linear regression with the mean squared error cost function, J(θ) is indeed a quadratic function of the parameters θ₀, θ₁, θ₂, ..., θn. Normally, the cost function J(θ) looks like a big bowl similar to Figure 3906a. This quadratic function will be ellipsis as shown in Figure 3906b. The red dots and lines shows that you run the gradient descent algorithm to find the global minimum, meaning converging to the global minimum.
Figure 3906a. Normal cost function J(θ).
Figure 3906b. Ellipsis and its contour of the quadratic function J(θ). The choice of the learning rate (α) in the Gradient Descent algorithm is crucial, and setting it too large or too small can lead to issues in the optimization process:
Choosing an appropriate learning rate is often an empirical process and depends on the specific problem and the characteristics of the cost function:
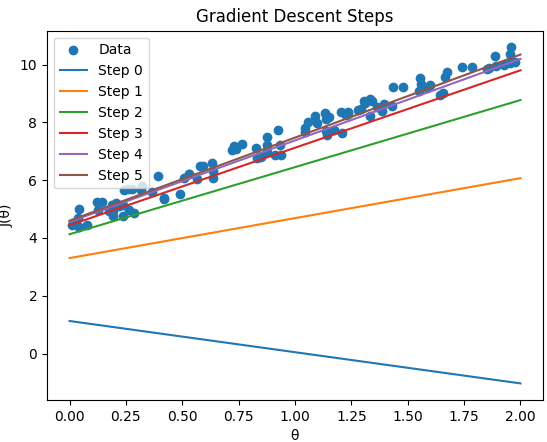
The choice of learning rate is one of the hyperparameters that can significantly impact the success of the Gradient Descent algorithm, and finding the right balance is essential for efficient and stable optimization. In practice, you will try a couple of values, and then find the most efficient α to find the global minimum. The script below shows the steps of example gradient descent and plots the hypothesis lines after each step with linear regression model, depending on learning rate. Code: This script shows how the gradient descent algorithm iteratively adjusts the parameters of a linear regression model to find the best-fitting line for the given data. Steps of gradient descent works within linear regression:
============================================ Gradient Descent algorithm: in the script below, we are chosing the initial point (0.8, -0.8) as starting θ0 and θ1 to find the minimum of f(θ). However, depending on different initial point, you can get different local lowest point. Code: Figure 3906c shows the the benefits of normalization in the gradient descent:
. Figure 3906c. Benefits of normalization in the gradient descent (Code). While gradient descent is a powerful optimization algorithm that can converge quickly, the guarantee of reaching the exact global optimum depends on various factors::
In traditional gradient descent, which involves computing the gradient of the cost function with respect to the parameters using the entire dataset, going through all data points can be computationally expensive, especially for large datasets, and is the most expensive one in the traditional gradient descent. This is because each iteration requires processing the entire dataset to calculate the gradient. ============================================
|
||||||||
| ================================================================================= | ||||||||
|
|
||||||||
 ------------------------------ [3974d]
------------------------------ [3974d]  ------------------------------ [3974e]
------------------------------ [3974e]  ------- [3974f]
------- [3974f]  ----------------------- [3974h]
----------------------- [3974h]  ----------------------- [3974i]
----------------------- [3974i]  -------------------- [3974k]
-------------------- [3974k]  - [3974l]
- [3974l]