Independent Component Analysis (ICA) - Python for Integrated Circuits - - An Online Book - |
||||||||
| Python for Integrated Circuits http://www.globalsino.com/ICs/ | ||||||||
| Chapter/Index: Introduction | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | Appendix | ||||||||
================================================================================= Independent Component Analysis (ICA) is a computational technique used in signal processing and statistics to separate a multivariate signal into additive, statistically independent components. It is particularly useful when we have a set of mixed signals and want to discover the underlying sources or components that contributed to the observed data. ICA is commonly used in various fields, including image processing, audio processing, neuroscience, and data analysis. Here's an explanation of how ICA works:
ICA relies on the assumption that the source signals are statistically independent. However, this assumption is not enough on its own; it also assumes that the source signals are non-Gaussian. The reason for this is that if the sources are Gaussian, then higher-order statistics (beyond mean and variance) are not informative, as the Gaussian distribution is fully characterized by its mean and covariance. ICA exploits higher-order statistics to identify the independent components. When the sources are non-Gaussian, there is more information in the higher-order moments of the distribution (skewness, kurtosis, etc.), and ICA can attempt to separate the sources based on these differences in statistical properties. Gaussian distribution, also known as the normal distribution, is characterized by a bell-shaped curve. In a Gaussian distribution, the majority of data points cluster around the mean, and the probability density decreases as we move away from the mean. On the other hand, an uniform distribution is non-Gaussian. In a uniform distribution, all values within a certain range have equal probability, and the probability density remains constant across that range. Visually, a uniform distribution would look like a flat line. ICA is valuable in applications where we want to uncover meaningful information from mixed data, such as:
Keep in mind that ICA relies on certain assumptions, such as the statistical independence of the sources, which may not always hold in practice. Additionally, the quality of the results obtained through ICA can be influenced by factors like the choice of optimization algorithm and the number of components to be extracted. Therefore, ICA is a powerful tool but requires careful consideration and parameter tuning in real-world applications. However, deconvoluting a colored image into separate single-color (channel) images using Independent Component Analysis (ICA) is not a common application of ICA. ICA is typically used for blind source separation, where the goal is to separate mixed sources into their original components. An example of an Independent Component Analysis (ICA) problem is: Assuming multiple speakers (sources) emitting sounds, which are recorded by microphones. The relationship between the sources and the microphone recordings is given by: where, is the recorded signal. is the mixing matrix (e.g. 3 by 3 in the example with 3 speakers). (i) is the original source signal. The distribution of the observed signals is related to the distribution of the sources through the demixing matrix w, so that we where, is essentially the inverse of the mixing matrix , denoted as , given by, where, represents the transpose of the demixing vector for the i-th source. In ICA, the objective is to find a demixing matrix w so that the estimated sources are statistically as independent as possible and have non-Gaussian distributions. The relationship between and can be given by, Equation 3911d reflects the relationship between the observed signals and the sources through the demixing process. Therefore, the ICA problem is to find a set of demixing vectors that, when applied to the microphone recordings, can separate the original source signals. The ICA algorithm aims to achieve this by exploiting the statistical independence of the sources. To address the problem, we would typically use an ICA algorithm, such as the FastICA algorithm. The goal of the algorithm is to estimate the demixing matrix by maximizing the non-Gaussianity or independence of the estimated source signals. Once is estimated, it can be used to reconstruct the original source signals from the microphone recordings.
Then, this expression represents a probability distribution for a random variable that is uniform on the interval . The indicator function is 1 when is in the interval and 0 otherwise. If , and has a uniform distribution on , then will have a uniform distribution on the interval . Namely, A = 2, and w = 1/2. Then, the density function should be, The factor of 1/2 ensures that the total probability integrates to 1 over the interval . Figure 3911a shows the density functions.
Figure 3911a. Density functions (code). Assuming the ICA model has logistic-distributed sources, then we have, Here, the source signal is less than or equal to a given value . Note that in the ICA, understanding the distribution of the source signals is crucial and different distributions may be assumed depending on the nature of the source signals and the specific assumptions made in an ICA model. The logistic distribution is just one possible choice. For n independent speakers The joint probability distribution of the vector of source signals is the product of the individual probability distributions of each source signal . We have, The probability distribution of the source signals can be factorized into the product of the individual marginal distributions of linear combinations of the observed signals , where,
The log-likelihood can be given by, The optimization is performed over a dataset with observations. The term with log is the log of the product of the PDFs of the linear combinations of the observed signals. Then, stochastic gradient descent can be used to maximize the log-likelihood, In stochastic gradient descent, at each iteration, a subset or a single data point is randomly chosen from the dataset, and the gradient is computed based on that subset or individual point. The update step for stochastic gradient descent can be given by, where, is the demixing matrix at iteration . is the learning rate. Once we have obtained the demixing matrix using an ICA algorithm, the next steps typically involve using to estimate the original independent source signals . This is done by applying the demixing matrix to the observed signals 3911b. In this step, we need to consider: i) Ordering of Sources:
ii) Scaling of Sources:
iii) Post-processing and Analysis:
iv) Validation and Fine-tuning:
v) Further Processing or Application:
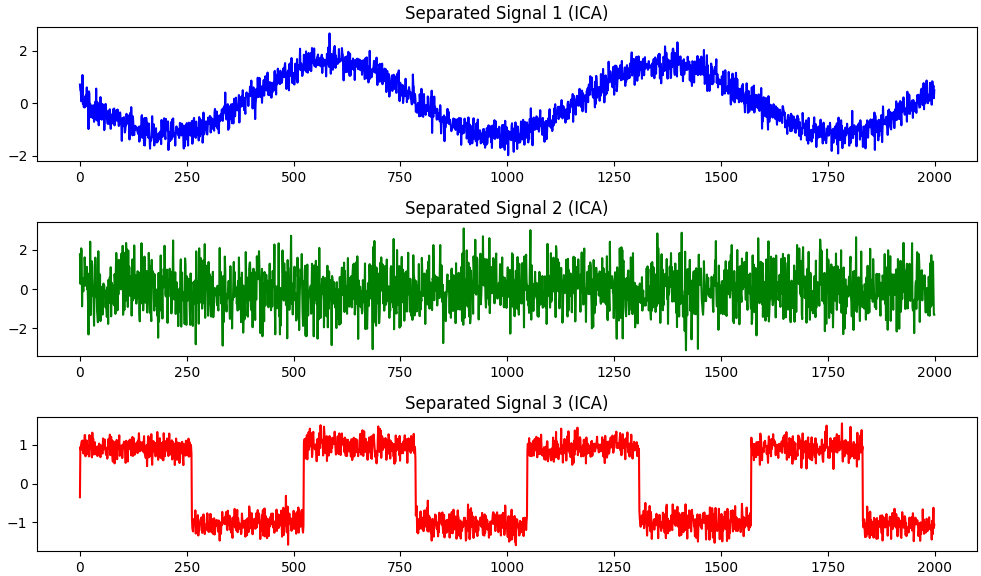
Figure 3911b shows generated synthetic mixed signals, and then ICA is used to separate them into their independent components. In this example, we generate three synthetic source signals (s1, s2, s3) and mix them using a predefined mixing matrix (A) to create mixed signals (X) with added noise. Then, we apply FastICA from scikit-learn to separate the mixed signals into their independent components (S_). Here, matplotlib is used to separate the signals. Note that ICA is a technique used in signal processing and data analysis, rather than a machine learning algorithm.
In ICA, the scenario where there are more sources (speakers) than observed signals (microphones) is commonly referred to as an "overdetermined" or "undercomplete" case. In other words, the number of independent sources is greater than the number of observed signals . This is a research problem. In an overdetermined ICA scenario:
When there are fewer independent sources (speakers) than observed signals (microphones) in Independent Component Analysis (ICA), this scenario is commonly referred to as an "underdetermined" case. In other words, the number of independent sources is less than the number of observed signals . In this situation, the underdetermined ICA case presents certain challenges and considerations:
On the other hand, determining the number of speakers (sources) in a given audio signal is a common challenge in various signal processing applications, including ICA or blind source separation. Several methods can be employed to estimate the number of speakers:
============================================
|
||||||||
| ================================================================================= | ||||||||
|
|
||||||||
 ------------------------------ [3911c]
------------------------------ [3911c] 
 ------------------------------ [3911h]
------------------------------ [3911h]  ------------------------------ [3911j]
------------------------------ [3911j]  ------------------------------ [3911k]
------------------------------ [3911k]  ----------------------- [3911l]
----------------------- [3911l]