Train/Test versus Model Accuracy - Python for Integrated Circuits - - An Online Book - |
||||||||
| Python for Integrated Circuits http://www.globalsino.com/ICs/ | ||||||||
| Chapter/Index: Introduction | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | Appendix | ||||||||
================================================================================= When comparing the statistics on the test set to the values for the training set in the context of model evaluation, the statistics on the test set reflect the accuracy of your model when applied to new and unseen data. Here's a recap of why this is the case:
The primary goal of predictive modeling is to build a model that generalizes well to new, unseen data. Therefore, the evaluation on the test set is crucial for assessing the model's real-world performance. If the model performs well on the test set, it suggests that it has learned meaningful patterns and can make accurate predictions when faced with new and previously unseen data. The statistics on the test set, not the training set, control the accuracy of your model when applied to new data. Here's why:
The main goal of predictive modeling is to build a model that can make accurate predictions when exposed to new, real-world data. Therefore, the statistics on the test set are the ones that control the accuracy of your model when applied to new data. If the model performs well on the test set, it suggests that it has successfully generalized from the training data and can make reliable predictions when presented with fresh, unseen data. The measured accuracy of a model can be misleading or inaccurate if the test dataset itself is flawed or not representative of the real-world data the model is expected to encounter. Here are some common scenarios in which the test dataset can impact the accuracy assessment:
To mitigate these issues, it's essential to carefully construct and curate the test dataset to make it as representative and reliable as possible. Additionally, techniques like cross-validation, where the dataset is split into multiple train-test subsets, can help provide a more robust assessment of model performance by reducing the impact of a single, potentially flawed test dataset. It is possible for one machine learning model to perform better during training while another model performs better during testing (evaluation) on the same dataset. This phenomenon is often referred to as "overfitting." Overfitting occurs when a model learns to fit the training data too closely, capturing noise and random fluctuations in the data rather than the underlying patterns. As a result, the model may perform exceptionally well on the training data but generalize poorly to unseen data, such as the test dataset or new, real-world data. This can lead to a situation where the training performance of one model is superior to another, but the test performance of the other model is better. Here's a typical scenario:
However, when you evaluate both models on a separate test dataset:
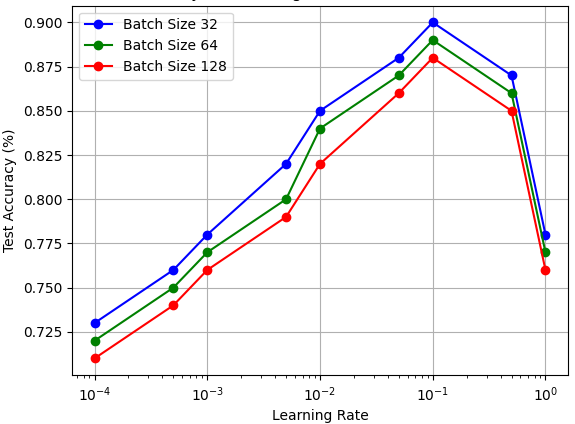
The goal in machine learning is to strike a balance between model complexity and generalization. You want a model that can capture the underlying patterns in the data without fitting noise too closely. Techniques like cross-validation, regularization, and early stopping can help mitigate overfitting and select models that perform well on both training and test datasets. Figure 4001 shows the test accuracy depending on learning rates. When the learning rate is too small, the model may take a long time to converge, i.e., to reach a minimum in the loss function. On the other hand, if the learning rate is too large, the model might overshoot the minimum and fail to converge:
Figure 4001. Test accuracy depending on learning rates (Code). ============================================
|
||||||||
| ================================================================================= | ||||||||
|
|
||||||||