Feature and Feature Vector (Extract Features) - Python for Integrated Circuits - - An Online Book - |
||||||||||||||||||||||||||
| Python for Integrated Circuits http://www.globalsino.com/ICs/ | ||||||||||||||||||||||||||
| Chapter/Index: Introduction | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | Appendix | ||||||||||||||||||||||||||
================================================================================= In machine learning and pattern recognition, a feature is an individual measurable property or characteristic of a phenomenon. In fact, the items (e.g. some specific columns in a csv file) that are inputted into the training model (and later used to make predictions) are called "features." In other words, the features is the representation of data in the form that can be used to map input data to the output, that is, the feature is a value that is passed as input to a model. "X" in the Naive Bayes classification and many other machine learning algorithms often represents the feature vector. A feature vector is a numerical representation of the features or attributes of a data point. Each component or element of the feature vector corresponds to a specific feature, and together they provide a concise and structured representation of the data for the algorithm to work with. In Naive Bayes classification for text, word frequencies, presence or absence of specific words, and other relevant properties of the text are used to create feature vectors. These feature vectors are numerical representations of the text data that the Naive Bayes algorithm uses for classification. This approach represents the document as a binary feature vector. Each element in the vector corresponds to the presence (1) or absence (0) of a particular word in the document: Each element in this vector in Equation 4026c represents the value of a specific feature. For instance, word Xi indicates {word i appears in an document} For multinomial Naive Bayes algorithm, we have, where,:
For instance, for house prices depending on the house size, we have the table below, Table 4015a. House prices depending on the house size.
xj in Table 4015a are considered as features. Features are also known as independent variables or predictors, and they are the input variables used to make predictions or estimate an outcome, which in this case is house prices. Similarly, the words in a document in Table 4015b also shows the feature vector xj. Table 4015b. House prices depending on the house size.
TF-IDF is a more advanced way to create feature vectors for text data. It takes into account the frequency of words in a document relative to their frequency across the entire dataset. This allows it to emphasize words that are important to a specific document while de-emphasizing In logistic regression, the logistic function maps any input value to a value between 0 and 1, namely hθ(x) ∈ [0,1], which can be interpreted as the probability of the observation belonging to one of the two classes. Then, we have hypothesis fuction given by: where:
One example is that both Multinomial Naive Bayes and the standard (single) Naive Bayes algorithm can work with feature vectors.
Training data sets require several example predictor variables to classify or predict a response. In machine learning, the predictor variables are called features and the responses are called labels. A feature vector is an ordered list of numerical properties of observed phenomena. Before being input into an ML model, raw data must be turned into feature vectors as shown in Figure 4105a.
Figure 4105b shows simplified overview of a machine learning workflow. The machine learning model is trained on input data gathered from different databases. Once it is trained, it can be applied to make predictions for other input data.
A good feature should have the following characteristics: Sequential API can be used to create a Keras model with TensorFlow (e.g. on Vertex AI platform). Then, the Keras Sequential API and Feature Columns can be used to build deep neural network (DNN). In combination with a trained model, the Keras model can be saved, loaded and deployed, and then the model can be called for making predictions. Wrangler and Data Pipeline features in Cloud Data Fusion can be used to clean, transform, and process data for further analysis. Batch serving and online serving are the two methods feature store offers for serving features. ============================================
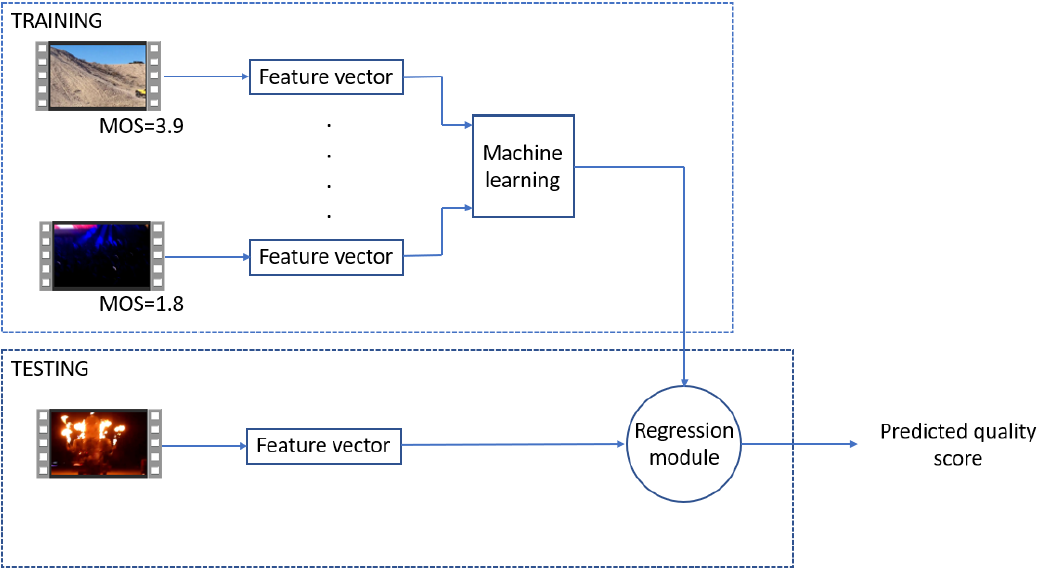
[1] Domonkos Varga, No-Reference Video Quality Assessment Based on Benford’s Law and Perceptual Features, Electronics 2021, 10, 2768.
|
||||||||||||||||||||||||||
| ================================================================================= | ||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||
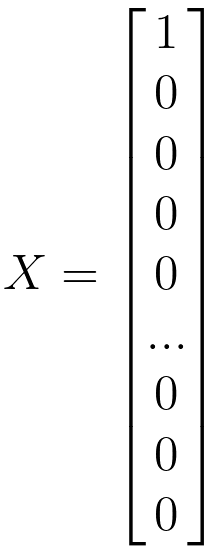 ------------------------------------------------------- [4105a]
------------------------------------------------------- [4105a]  --------------------------------------- [4105c]
--------------------------------------- [4105c] 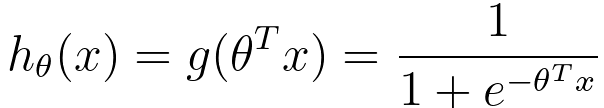 ---------------------- [4015d]
---------------------- [4015d]