Support-Vector Machines(SVM)/Support-Vector Networks(SVN) - Python for Integrated Circuits - - An Online Book - |
||||||||||||||||||||||||||||||||||||||||||||||
| Python for Integrated Circuits http://www.globalsino.com/ICs/ | ||||||||||||||||||||||||||||||||||||||||||||||
| Chapter/Index: Introduction | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | Appendix | ||||||||||||||||||||||||||||||||||||||||||||||
================================================================================= Support-vector machines (SVMs) are a type of supervised learning algorithm used for classification and regression tasks. The primary goal of an SVM is to find a hyperplane that best separates data points belonging to different classes. That is, the goal is to find a hyperplane that maximizes the margin between different classes of data points. This hyperplane is sometimes referred to as the "maximum margin separator" or "optimal margin classifier" because it achieves the maximum separation between classes by having the largest possible margin. The term "support vector machine" was coined by Vladimir Vapnik and his colleagues in the 1990s:
Figure 4270aa. Support vectors in SVM ( Code). SVMs are particularly effective in high-dimensional spaces and are well-suited for tasks: i) Image classification. ii) Text categorization. In practice, we can simplify SVM as optimization of margin classifier and kernel tricks. For SVM, we have: i) SVMs are often used for binary classification tasks, where the labels are typically represented as -1 and +1 to indicate the two classes, namely, the labels can be given as y ∈ {-1, +1}. ii) SVMs aim to separate data into two classes, and the output of an SVM is typically in the form of -1 or +1, indicating the predicted class. That is, it has h output values in {-1, +1}. iii) Its decision function is often represented as g(z), where z is the output of the SVM (the result of the dot product between the feature vector and the learned weights), and it is usually expressed as: g(z) = 1 if z ≥ 0 g(z) = -1 if z < 0 Text classification, also known as document classification or supervised text categorization, involves assigning predefined labels or categories to text documents based on their content. The goal is to train a model to recognize patterns and associations between the content of documents and the appropriate labels. To do this, you need a labeled dataset where each document is associated with its correct category or label.
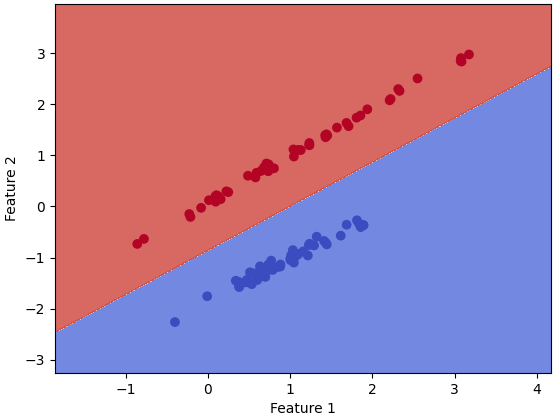
Figure 4270ab. SVM classifier. As an example of Support Vector Machines (SVM) algorithm applications, assume you want to separate two classes (blue and green) in a way that allows you to correctly assign any future new points to one class or the other. SVM algorithm attempts to find a hyperplane that separates these two classes with the highest possible margin. If classes are entirely linearly separable, then a hard margin can be used. Otherwise, it requires a soft margin, where some points can be treated as outliers. The points that end up on the margins are known as support vectors as shown in Figure 4270b.
Figure 4270b. Illustration of Support Vector Machines (SVM) algorithm. Key Points:
Support Vector Machines are a powerful and widely used machine learning algorithm for classification and regression tasks. Support Vector Machine (SVM), [1-2] also called as support-vector networks(SVN), is one of the traditional machine learning models. The function of an SVM is to identify the hyperplane (i.e., decision boundary) with the widest separation between two classes of training data, and thus the SVM is designed to determine the hyperplane at which the margin between two classes of data is maximized. Support Vector Machines (SVMs) are a class of supervised learning algorithms that can be used for both classification and regression tasks. They are particularly effective in high-dimensional spaces and are widely used for solving complex classification problems. Basic Concepts:
For SVMs, the decision function is typically given by, where,:
We can also use the format of logistic regression given by, with consideration of θ as, where, θ0 is b in Equation 4207a. θ1, θ2, and θ3, represented by w in Equation 4207a. Working Principle: Given a labeled training dataset (input data points with corresponding class labels), the goal of SVM is to find the optimal hyperplane that maximizes the margin between the classes. The mathematical formulation involves solving a quadratic optimization problem to determine the hyperplane's parameters. For a binary classification problem, the objective is to find a hyperplane that satisfies: where:
For SVM, we can transform (θ0, θ1, ..., θn) into (b, w1, ..., wn): Here, to represent the intercept and to represent the coefficients of features. Inequality 4207b is related to the SVM optimization problem, where we try to find a hyperplane defined by the weights (w) and bias (b) that maximizes the margin between two classes. The goal of the SVM is to maximize the margin while ensuring that all data points are correctly classified. The regularization term is given by, The regularization term is a form of L2 regularization, which is also known as "ridge regularization" or "Tikhonov regularization." L2 regularization aims to prevent overfitting in machine learning models by adding a penalty term that discourages large values in the weight vector w. In the SVM formulation, you aim to maximize the margin between classes while minimizing the norm of the weight vector (||w||) to prevent overfitting. By combining Equations 4207a and 4207b, we have, where, g is the activation function. n is the number of input features. Equation 4207bba is a basic representation of a single-layer neural network, also known as a perceptron or logistic regression model, depending on the choice of the activation function g. From Equation 4207bba, we can derive different forms or variations by changing the activation function, the number of layers, or the architecture of the neural network as shown in Table 4270a. Table 4270a. Different forms or variations of Equation 4207bba.
The functional margin of hyperplane defined by Equation 4207bb can be given by, Then, we can have, where, i = 1, 2, ..., m. Equation 4207bd is used to compute the distance between the data point (x(i), y(i)) and the decision boundary by the parameters w and b. We expect that, If y(i) = 1, then we have wTx(i) + b >> 0. If y(i) = -1, then we have wTx(i) + b << 0. Then, Equation 4207bd will positively be very large in both cases above. And, as long as Equation 4207bd is greater than 0, then, h(x(i)) = y(i). Then, the training set of functional margin is given by, Here, we assume the training is linearly separable. We have the worst case in (i = 1, 2, ..., n) given by, We try to make the margin as large as possible. In SVM, you typically want to find the hyperplane (decision boundary) that maximizes the margin between the classes. The equation for the decision boundary in an SVM is, wTx(i) + b = 0 --------------------------------------- [4207bg] In order to ensure that the margin between the classes is determined by the distance of the data points to the hyperplane, rather than the scale of the weight vector, we often normalize the parameters by using, or, This normalization doesn't change the orientation of the decision boundary (and thus the classification is not changed) but only scales it to have a unit length. Then, the SVM decision boundary becomes: This normalization can make the SVM training more numerically stable and helps ensure that all the support vectors lie at a distance of exactly 1 from the decision boundary, simplifying the margin calculation. In practice, many SVM implementations handle this normalization automatically. The optimization problem aims to minimize the norm of the weight vector (||) subject to the constraint that all data points are classified correctly (or with a margin of at least 1). The classifier of SVMs can be represented by the equation wTx + b = 0 . In SVM, this equation defines the decision boundary, which is a hyperplane that separates data points in a binary classification problem. And, one side of the hyperplane represents wTx + b > 0 (namely, hw,b(x) = +1), and the other side represents wTx + b < 0 (namely, hw,b(x) = -1). For the SVM case, the geometric margin at (x(i), y(i)) is given by, The signed distance from the decision boundary to the data point (x(i)). It indicates which side of the hyperplane the data point falls on. If ŷ(i) is positive, it means the data point is correctly classified, and if it's negative, it's misclassified. Equation 3815bl below provides a more general expression for ŷ(i), which includes the class label y(i). This is an extension to handle both sides of the decision boundary. If y(i) is positive, the data point should have a positive ŷ(i) to be correctly classified, and if y(i) is negative, ŷ(i) should be negative for correct classification. In Support Vector Machines (SVM), the goal of choosing the weight vector "w" and bias term "b" is to maximize the geometric margin for the optimal margin classifier. This choice is fundamental to the SVM algorithm for several reasons:
Equation 3815bm shows to how to maximize the geometric margin (γ) for the optimal margin classifier: This inequality is hard to address if we do not use a gradient descent and initially known local optima, then it implies that y(i)(wTx(i) + b) ≥ 0, because: Multiply both sides of Inequality 3815bm by ||w||: Let , so the inequality becomes: Now, because ||w|| is a positive value and is also non-negative (), is still non-negative (). Thus, y(i)(wTx(i) + b) ≥ 0 holds. Based on Inequality 3815bm, we can have, Multiply both sides by ||w||, then we have, Now, the key insight is that the margin between the two classes, which is 2/||w||, is maximized when 1/||w|| is maximized. Thus, 1/||w|| is the quantity we want to maximize, and we can rewrite it as: Therefore, to maximize 1/||w||, we need to minimize the denominator to be 1. This constraint ensures that data points are correctly classified, and the margin is maximized. For the margin, we have, The decision boundary of an SVM is defined by the hyperplane. The vector is orthogonal (perpendicular) to this decision boundary. As an example, if w is
Figure 4270ba. Optimization of w and b to satisfy the formulas 4207b and 4207ba. Code. Figure 4270bb shows the calculation of the distances of the points to the hyperplane with Inequality 3815bm.
Figure 4270bb. Calculation of the distances of the points to the hyperplane. Code. In SVMs, for training examples x SVMs work by finding a hyperplane that best separates data points in a high-dimensional and even infinite-dimensional space. The Representer Theorem is a theoretical result in kernel machines. If the data can be mapped into a high-dimensional feature space using a kernel function, then the solution to the optimization problem in the SVM formulation can be expressed as a linear combination of the training examples in that feature space. With more complicated expression, Equation 3815bs can be given by, Where:
Plug Equation 3815bs into Equation [4207ba, we can have, Using the properties of the norm and the dot product, Then, we can expand the dot product, It can be written as, where, <x(i), x(j)> represents the inner product (or dot product) between the data points x(i) and x(j), e.g. two different vectors, where is the only place in which the feature vectors appear. To find the minimum of (1/2)||w||2, we need to minimize it with respect to , subject to the constraints imposed by the Lagrange multipliers and the data points. The optimization problem can be stated as: Minimize (1/2)||w||2 with respect to , subject to the constraints: This is a quadratic optimization problem with linear constraints. We can use techniques like the Lagrange multiplier method or a quadratic programming solver to find the minimum of (1/2)||w||2 subject to these constraints. The solution will give you the optimal values of , and from that, you can compute the minimum value of (1/2)||w||2. The solution will also give us the optimal values of , which will be the decision boundary for a support vector machine (SVM) classifier. Then, the question is to maximize the term below: Subject to: The one, presented by the formulas 3815cb, 3815cc and 3815cd, is the dual form of the SVM optimization problem. The dual form is often used due to its computational benefits and strong duality properties. The objective of this optimization problem is to find the optimal values of that maximize the margin while satisfying the constraints. The two statements 3815cc and 3815cd are common conditions in the context of support vector machines (SVMs), and they are often associated with the Karush-Kuhn-Tucker (KKT) conditions for SVM optimization problems. In SVM, the Lagrange multipliers () should be greater than zero. These non-zero values of correspond to support vectors, which are the data points that are closest to the decision boundary (the support vectors define the position of the decision boundary). These support vectors have non-zero Lagrange multipliers. The constraint 3815cd ensures that the Lagrange multipliers are chosen in a way that satisfies the SVM duality conditions. Specifically, it enforces the complementary slackness condition, which implies that either is zero or the corresponding data point is correctly classified and lies on or within the margin. In other words, this condition ensures that for correctly classified points (those on or within the margin), will be non-zero, and for incorrectly classified points (those outside the margin), will be zero. In dual problem for the SVM, Inequality 3815cd is modified as following, where, is the regularization parameter that controls the trade-off between maximizing the margin between the classes and minimizing the classification error. SVMs can be extended to handle non-linearly separable data by using the "kernel trick." The kernel function computes the inner product of data points in a higher-dimensional space without explicitly transforming the data. This allows SVMs to effectively capture complex relationships between features. The steps of how kernels are applied in machine learning, particularly in the SVMs and kernel methods are: 1) Write algorithm in terms of <x(i), x(j)> (or <x, z>): This step involves expressing the algorithm or model in terms of the dot product between input data points. This is typically done when you have a linear algorithm, and you want to extend it to work in a higher-dimensional feature space without explicitly computing the transformation. 2) Let it map from your input feature x to some high-dimensional set of feature φ(x): In this step, you can map your original data from a lower-dimensional feature space to a higher-dimensional feature space using a function φ(x). This mapping can be complex and computationally expensive, but it's a key concept in kernel methods. 3) Find a way to compute: where, This is where the kernel trick comes into play. Instead of explicitly computing the high-dimensional feature vectors φ(x) and φ(z), you find a kernel function K(x, z) that allows you to compute the dot product in the higher-dimensional space without explicitly mapping the data points. Common kernel functions include the linear kernel, polynomial kernel, and radial basis function (RBF) kernel. 4) Replace <x, z> in the algorithm with K(x, z): This is the final step where you substitute the original dot product <x, z> in your algorithm with the kernel function K(x, z). This allows you to work in the high-dimensional feature space without the computational cost of explicitly computing φ(x) and φ(z). Support Vector Machines are a powerful and flexible tool in the realm of machine learning, often used for various real-world applications like image classification, text classification, and bioinformatics. There are several Python libraries that you can use to train Support Vector Machine (SVM) models. Some of the popular ones include:
For most general use cases, scikit-learn is the recommended choice due to its user-friendly interface, extensive documentation, and active community support. However, you might choose a different library based on specific requirements or if you are working on a particular research project. SVMs are a set of supervised learning methods used for: The advantages of SVMs are: The disadvantages and limitations of SVMs are: The reasons why SVMs is less prone to overfitting are mainly due to the structural risk minimization principle and the margin maximization concept:
Figure 4270bc shows the flowchart of WMFPR (wafer map failure pattern recognition) which is based on a two-stage framework. Stage 1 determines whether a wafer map exhibits a failure pattern, while Stage 2 identifies the pattern type. In this flowchart, an SVM is used as a classifier. During the training phase, the SVMs determine the support vectors in the training data, which are applied to predict new wafer maps during the test phase. The main advantage of the two-stage framework is that the parameters can be trimed to optimize the tradeoff between the false-positive rate and the false-negative rate at Stage 1.
In ML programming, we need to include the minimization of objective function: where,
The objective of the SVM is to minimize the combination of these two terms. The program also need to include the subject to constraint: This constraint ensures that each training example is correctly classified, with a margin of at least 1. The slack variable allows for some flexibility, allowing points to be on the wrong side of the decision boundary but penalizing such misclassifications in the objective function. Machine learning methods such as logistic regression, SVM with a linear kernel, and so on, will often require that categorical variables be converted into dummy variables. For example, a single feature Vehicle would be converted into three features, Cars, Trucks, and Pickups, one for each category in the categorical feature. The common ways to preprocess categorical features are: Support Vector Machines (SVM) are a versatile and powerful machine learning algorithm used for both classification and regression tasks. Here are some applications of Support Vector Machines:
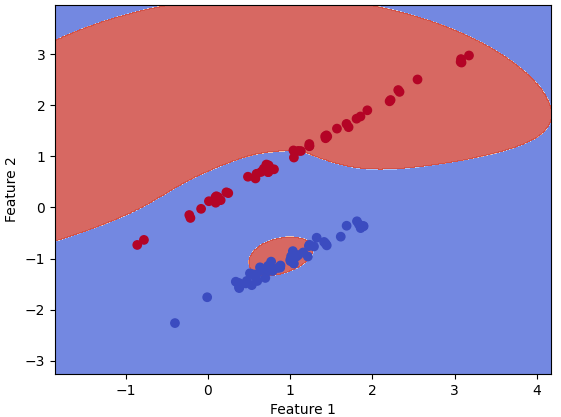
These are just a few examples, but SVMs can be applied to a wide range of domains and problems where classification or regression is required. Table 4270bb lists SVMs with different Kernel visulizations. Table 4270bb. SVMs with different Kernel visulizations.
As shown in Table 4270c, batch gradient descent can also be used for training SVMs, particularly for solving the soft-margin SVM optimization problem. However, note that SVMs are often trained using optimization algorithms that are specifically designed for their objective function, such as the Sequential Minimal Optimization (SMO) algorithm a Figure 4270bd shows comparison between hard margin without C and soft margin with C in SVMs see page3808.  Figure 4270bd. Comparison between hard margin without C and soft margin with C in SVMs. (code)
Table 4270c. Algorithms used by SVM.
============================================ Defect Detection and Classification. Code: ============================================
[1] Ming-Ju Wu, Jyh-Shing R. Jang, and Jui-Long Chen, Wafer Map Failure Pattern Recognition and Similarity Ranking for Large-Scale Data Sets, IEEE TRANSACTIONS ON SEMICONDUCTOR MANUFACTURING, 28(1), Feb 2015.
|
||||||||||||||||||||||||||||||||||||||||||||||
| ================================================================================= | ||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||



 -------------------------------- [4207aa]
-------------------------------- [4207aa]  --------------------------------- [4207ab]
--------------------------------- [4207ab] ------------------- [4088bb]
------------------- [4088bb]  --------------------------------- [4207ba]
--------------------------------- [4207ba]  --------------------------------- [4207bba]
--------------------------------- [4207bba]  ------------------------------ [4207bbb]
------------------------------ [4207bbb]  --------------------------------- [4207bbc]
--------------------------------- [4207bbc]  , which is the formula for linear regression.
, which is the formula for linear regression. --------------------------------- [4207bd]
--------------------------------- [4207bd]  --------------------------------- [4207be]
--------------------------------- [4207be]  --------------------------------- [4207bj]
--------------------------------- [4207bj]  -------------------------------------- [3815bk]
-------------------------------------- [3815bk]  -------------------------------------- [3815bl]
-------------------------------------- [3815bl]  -------------------------------------- [3815bm]
-------------------------------------- [3815bm]  --------------------------- [3815bp]
--------------------------- [3815bp]  --------------------------- [3815br]
--------------------------- [3815br] 

 --------------------------- [3815bs]
--------------------------- [3815bs]  --------------------------- [3815bs]
--------------------------- [3815bs]  --------------------------- [3815bt]
--------------------------- [3815bt]  --------------------------- [3815bu]
--------------------------- [3815bu]  --------------------------- [3815bv]
--------------------------- [3815bv]  --------------------------- [3815bw]
--------------------------- [3815bw]  --------------------------- [3815ca]
--------------------------- [3815ca]  ----------------------- [3815cb]
----------------------- [3815cb]  ----------------------- [3815cd]
----------------------- [3815cd] 

 -------------------------------------- [3815dy]
-------------------------------------- [3815dy]