Supervised Machine Learning - Python for Integrated Circuits - - An Online Book - |
||||||||
| Python for Integrated Circuits http://www.globalsino.com/ICs/ | ||||||||
| Chapter/Index: Introduction | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | Appendix | ||||||||
================================================================================= Supervised learning is a machine learning paradigm where an algorithm learns to make predictions or decisions based on labeled training data. In supervised learning, the algorithm is provided with a dataset that consists of input-output pairs, where the input represents the features or attributes of the data, and the output represents the corresponding labels or target values that you want the algorithm to predict. The main goal of supervised learning is to learn a mapping or a function from the input data to the output labels so that the algorithm can make accurate predictions on new, unseen data. During the training process, the algorithm adjusts its internal parameters through optimization techniques to minimize the difference between its predictions and the true labels in the training data. Supervised learning is widely used in various fields, including natural language processing, computer vision, healthcare, finance, and many other domains where predictive modeling is essential. It's called "supervised" learning because the algorithm learns from a "teacher" or supervisor who provides the correct answers (labels) during training, and the algorithm's performance is evaluated based on its ability to make accurate predictions on new, unseen data. Figure 4323a shows the supervised machine learning architecture.
In the keyword analysis with supervised machine learning approach by Kurian et al., [1] a total of 15,000 incidents were manually classified: descriptive labels, actual and potential risk scores, and consequence labels (environment, finance, health/safety, and reputation) were applied to each incident. The incident reports were then divided into training and test data, and the machine learning algorithm used the training data to predict labels for the test data. The result of this research was a machine learning algorithm that could apply labels to incidents with 75–90% accuracy (depending on the label), and the outputs were used to develop risk matrices and to analyze trends in incidents. Such machine learning can be used to remove human bias, and this method allowed for consistent reporting of incidents. However, some incident reports lacked the detail required for classification, therefore it was impossible to completely remove bias as using a supervised learning model implies manual training. Additional keyword analysis can be applied to increase the accuracy of machine learning classification. This ML research provides significant changes to the current system of incident reporting. Example applications of supervised machine learning approach are [1]:
i.b) The data in the
incident database was prepared for the machine learning classification. The
TfidfVectorizer feature from Python’s scikit-learn library was used to transform each incident report into a numerical vector, and thus, the
incident database is transformed into a matrix ( incident database, or similar to a dictionary). [3] Note that few other libraries can also be used to convert incident documents into numerical vectors (see page4316). Such manually classified incidents were then separated into training and test data sets, containing 70% and 30% of the data, respectively. [4] The occurrence of each term (word) is counted, and weights are applied by
comparing how frequently a term is found in a document (report) versus the entire
dictionary. The result is the transformation of text to a numerical
vector. Such numerical vectors of the incident reports in the training set were expressed graphically, and a classifier was used to
generate decision boundaries used to classify data. For every
term found in an incident document, a count is applied
to the position of the word in the incident dictionary. The most accurate classifier for
categorizing incident reports is Linear Support Vector Classifier (Linear SVC), boasting accuracies close
to 90% when predicting labels. [5] In those cases, the metrics used
were the confusion matrix, classification report, and accuracy score. [6] The confusion matrix was calculated by counting the number of true positives, true negatives, false positives, and false negatives. The confusion matrix was used to demonstrate
how a classifier makes predictions for labels and requires the true and predicted classifications of the model. In a confusion matrix, the true label can be found on the y-axis and the predicted label on the x-axis. The classification report delivers precision, recall, F1-score, and support with inputs of the actual and predicted labels. ii.a) Logistic
regression. Within supervised learning, if we are to predict numeric values, then it
is called regression. For instance, if the aim is to predict
the scores the student is going to have (numeric value), this
comes under regression. ============================================
[1] Daniel Kurian, Fereshteh Sattari, Lianne Lefsrud, Yongsheng Ma, Using machine learning and keyword analysis to analyze incidents and reduce risk in oil sands operations, Safety Science, 130(2020), 104873.
|
||||||||
| ================================================================================= | ||||||||
|
|
||||||||




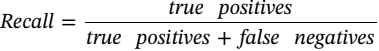 --------------------------------- [4323b]
--------------------------------- [4323b]