=================================================================================
When we have both dependent and independent variables in our dataset, the chi-square test for feature selection helps determine which independent variables (features) have a significant relationship with the dependent variable (target). This process is generally used when dealing with categorical data:
- Prepare the data
- Ensure that the variables are categorical. If they're not (e.g., they're numerical), we may need to bin them into categories.
- Construct a contingency table for each independent variable
- For each independent variable, create a contingency table with the dependent variable. This table counts occurrences of each combination of categories between the independent and dependent variable.
- Apply the Chi-Square Test
For each contingency table corresponding to each independent variable, compute the Chi-Square statistic. This test evaluates whether the distribution of the categories of the independent variable differs significantly across the categories of the dependent variable. Steps for Chi-Square Test:
- Calculate the expected counts: For each cell in the contingency table, calculate the expected count, which is what we would expect if there was no association between the independent and dependent variable.
 -------------------------- [3267a] -------------------------- [3267a]
- Compute the Chi-Square statistic: This is calculated using the formula:
 -------------------------- [3267b] -------------------------- [3267b]
where the summation is over all cells in your contingency table.
- Determine significance: Compare the computed Chi-Square statistic to the critical value from the Chi-Square distribution table at your desired significance level (commonly 0.05). If the statistic is greater than the critical value, there is a significant association between the independent and dependent variables. Alternatively, you can use the p-value.
- Adjust for multiple comparisons (if necessary)
- If we are testing multiple features, consider adjusting for multiple comparisons to control the family-wise error rate, using methods like the Bonferroni correction.
An example is given by script:

Output:

The output provides Chi-square statistics and p-values for two features, Feature1 and Feature2, in relation to the target variable Target:
- Interpretation of Results
- Feature1
- Chi-square statistic for Feature1: 1.0
- p-value for Feature1: ~0.32
The p-value (0.3173) is greater than 0.05, indicating that there is no statistically significant association between Feature1 and Target. In other words, the variation in the target variable Target is not significantly associated with the categories in Feature1. Therefore, for Feature1, the Chi-square test suggests no significant relationship with the target variable Target.
- Feature2
- Chi-square statistic for Feature2: 0.0
- p-value for Feature2: 1.0
The p-value (1.0) is much greater than 0.05, indicating that there is absolutely no evidence of an association between Feature2 and Target. This means that Feature2 and Target are completely independent of each other in this dataset.
Therefore,
for Feature2, the Chi-square test strongly suggests no relationship with the target variable Target.
On the other hand, to perform Chi-square feature selection with sklearn.feature_selection (for chi2), we need to encode the categorical variables into numerical values, as the chi2 function in sklearn works with numerical data. script:

Output:
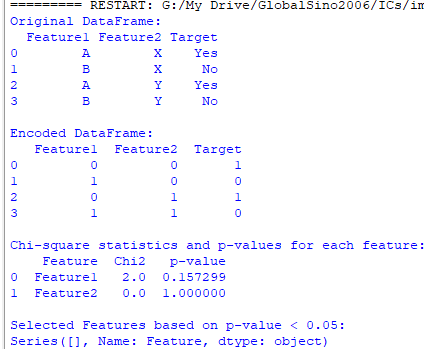
In this script, categorical variables are converted into numerical values using LabelEncoder. The features are separated into the features (X) and the target variable (y). Chi-square Test has been performed by using chi2, from sklearn, to compute Chi-square statistics and p-values for each feature. p-value represents the probability that the observed association is due to chance.
Note that the two methods above use different statistical calculations so that the obtained p-values are different:
- Method 1: Chi-Square Test Using scipy.stats.chi2_contingency
In this method, we used the chi2_contingency function from the scipy.stats module to calculate the Chi-square statistic and p-value. This method involves creating a contingency table (cross-tabulation) of the observed frequencies for each combination of feature values and the target variable. The Chi-square test then compares the observed frequencies with the expected frequencies under the null hypothesis that the features and the target variable are independent: - Create a contingency table using pd.crosstab().
- Use chi2_contingency() to compute the Chi-square statistic and p-value.
This method directly calculates the Chi-square statistic based on the observed and expected frequencies in the contingency table. The scipy.stats.chi2_contingency method considers the relationship between all categories of a feature and the target variable simultaneously, using a contingency table.
- Method 2: Chi-Square Test Using sklearn.feature_selection.chi2
In this method, we used the chi2 function from the sklearn.feature_selection module to perform Chi-square feature selection. This function is designed for feature selection in machine learning and assumes that both the features and the target variable are encoded as numerical values. It computes the Chi-square statistic for each feature independently, based on the following steps: - Encode the categorical variables to numerical values using LabelEncoder.
- Compute the observed frequencies for each feature-target pair.
- Calculate the Chi-square statistic based on the observed and expected frequencies.
This sklearn.feature_selection.chi2 method treats each feature independently and calculates the Chi-square statistic by comparing the observed frequencies of each feature's categories with the target variable. The differences in these calculations discussed above result in different p-values. Specifically, chi2_contingency is used for testing the independence between two categorical variables in a more general context, whereas sklearn.feature_selection.chi2 is tailored for feature selection in machine learning, focusing on each feature's relationship with the target variable independently.
Both methods can still use the 0.05 p-value threshold to determine significance. However, the interpretation and application context differ slightly between the two methods:
- Method 1: scipy.stats.chi2_contingency
This method calculates the p-value based on the contingency table, which considers the entire distribution of the feature with respect to the target variable. A p-value below 0.05 indicates that there is a statistically significant association between the feature and the target variable. This method is more suitable for general statistical analysis where we are interested in testing the independence between two categorical variables.
===========================================
|
