=================================================================================
Using machine learning responsibly and ethically involves a set of practices and considerations designed to ensure that machine learning technologies are developed and deployed in ways that are safe, fair, and beneficial to society. Some key aspects of responsible and ethical use of machine learning are: - Fairness: Ensuring that AI systems do not perpetuate, amplify, or introduce biases against certain groups or individuals. This includes addressing issues in training data, model decisions, and ensuring equitable impacts across different demographics.
- Transparency: Making the workings of AI systems understandable to users and other stakeholders. This includes explaining how and why decisions are made by AI systems, especially in critical applications like healthcare, law enforcement, and finance.
- Accountability: Establishing mechanisms to hold designers, developers, and deployers of AI systems accountable for the outcomes of their technology. This also includes having clear protocols for when things go wrong or decisions need to be reviewed.
- Privacy: Protecting the data used by machine learning systems. This involves implementing robust data protection measures, ensuring data is collected and used in compliance with privacy laws and norms, and minimizing invasive data collection practices.
- Security: Ensuring that machine learning systems are safe from attacks and cannot be easily manipulated or misused. This includes protecting against adversarial attacks that can trick or bypass AI systems.
- Sustainability: Considering the environmental impact of developing and running machine learning models, especially the energy-intensive processes involved in training large models.
- Ethical Deployment: Reflecting on the broader implications of deploying machine learning systems, including potential impacts on employment, power dynamics, and societal norms.
Promoting responsible machine learning also involves the participation of diverse teams in AI development, ongoing monitoring of AI systems in deployment, and engaging with various stakeholders, including the public and domain experts, to guide ethical considerations. The goal is to ensure that machine learning technology contributes positively to society and minimizes harm.
Using machine learning responsibly and ethically in the semiconductor industry involves applying AI technologies in ways that are considerate of ethical standards, societal impacts, and regulatory guidelines: - Bias and Fairness: Ensuring that machine learning algorithms do not perpetuate or amplify biases found in data or decision-making processes. This is crucial in applications like automated hiring, quality control, and supply chain decisions, where biased outputs could lead to unfair practices or discrimination.
- Transparency and Explainability: Making machine learning models transparent and understandable to users and stakeholders. In the semiconductor industry, where decisions based on AI can significantly impact production and innovation, stakeholders should be able to understand how and why decisions are made.
- Data Privacy: Safeguarding the privacy of data used in machine learning processes. This includes respecting data protection laws and ensuring that data collected for machine learning purposes is handled securely, particularly when sensitive or proprietary information (such as intellectual property or personal employee data) is involved.
- Security: Protecting AI systems from malicious attacks and ensuring their robustness. This is vital in the semiconductor industry because cybersecurity vulnerabilities can not only disrupt operations but also lead to significant financial and reputational damage.
- Sustainability: Considering the environmental impact of deploying machine learning technologies. For instance, optimizing resource usage and reducing waste in production processes can be achieved with AI, but the energy consumption of training large models must also be considered.
- Compliance with Regulations: Adhering to international standards and regulatory requirements, such as the General Data Protection Regulation (GDPR) in Europe or specific guidelines around AI and automation in industrial settings.
- Impact on Employment: Addressing the workforce implications of automating processes traditionally performed by humans. This includes retraining programs, managing transitions for affected employees, and ensuring that AI supports rather than replaces human workers where possible.
For instance, in semiconductor manufacturing, the implementation of machine learning models for failure analysis can encounter significant challenges due to reporting bias, particularly in the recording of wafer defects. A prevalent issue arises when minor defects detected through manual inspections by technicians are not recorded in the historical data used for training predictive models. Often, these minor defects do not meet the stringent detection thresholds set for automated inspection tools, resulting in their exclusion from the dataset. Consequently, the model trained on this data may develop a skewed understanding of the defect landscape, overlooking these less conspicuous yet potentially critical anomalies. This incomplete data representation undermines the model’s ability to accurately predict failures, leading to inefficiencies in maintenance schedules and possibly increased production costs due to undetected defects escalating into more severe failures. Such scenarios highlight the crucial need for comprehensive data collection practices that encompass a broader range of defect types to enhance the reliability and effectiveness of predictive maintenance systems in the semiconductor industry.
Another example of selection bias is that you are tasked with developing a machine learning model to predict equipment failures in a semiconductor manufacturing plant. The model is trained using historical maintenance data from equipment primarily located in high-volume production lines. In this model, due to the focus on high-volume production lines, the maintenance data from lower-volume or older production lines might be underrepresented in the training dataset. This can lead to a situation where the model is less effective at predicting failures in these less-represented lines because it has predominantly learned from the conditions and failure patterns of high-volume environments. Such a model might fail to generalize well across different production settings, leading to increased downtime and maintenance challenges in parts of the facility not adequately represented in the training data. This selection bias can compromise the model's accuracy and reliability, impacting the overall efficiency of maintenance operations in the semiconductor manufacturing process.
Confirmation bias in machine learning refers to a situation where a model or its developers give more weight to data or results that confirm their pre-existing beliefs or hypotheses while disregarding or minimizing evidence that contradicts them. This bias can manifest in several stages of the machine learning process: - Data Collection: Confirmation bias can influence which data are collected for training a model. For example, if a team believes that a particular feature (like age or location) is crucial for predicting a target outcome, they may intentionally or unintentionally collect more data that reinforce this belief, potentially overlooking other important features.
- Feature Selection: During the feature selection phase, there might be a tendency to choose features that fit preconceived notions about what should be important, rather than letting the data and a comprehensive analysis guide these decisions.
- Model Training: Confirmation bias can also appear during the training process if the model is repeatedly tuned to perform well on specific subsets of data that confirm certain theories about the data, ignoring the model’s performance on other subsets that might lead to different conclusions.
- Interpretation of Results: After training, there can be a tendency to focus on and highlight model predictions that align with expected or desired outcomes, while downplaying or misunderstanding predictions that do not fit these expectations.
- Feedback Loops: If a model's predictions are used as a basis for further data collection and training, confirmation bias can lead to feedback loops. For example, if a predictive policing model is biased to predict higher crime rates in certain areas and law enforcement resources are subsequently concentrated there, more crimes might be recorded in those areas simply due to increased surveillance, thus 'confirming' the original model’s predictions and biasing future predictions even further.
Confirmation bias can severely compromise the objectivity of a machine learning model, leading to skewed or inaccurate outputs. It is crucial for teams working on machine learning projects to employ rigorous, unbiased methodologies throughout the development process and to constantly challenge their assumptions to mitigate the effects of confirmation bias. The relationship between confirmation bias, hypothesis, and world data is a significant aspect of both scientific research and real-world decision-making. Each element interacts with the others in a way that can critically impact the conclusions we draw and the actions we take. Hypothesis is essentially a proposed explanation made on the basis of limited evidence as a starting point for further investigation. It is a statement that can be tested by gathering and analyzing data. Hypotheses are crucial in research and data analysis as they guide the types of questions we ask and the data we collect.
Automation bias in machine learning refers to the tendency of human operators to favor suggestions or decisions made by automated systems, even when they contradict better judgement or more accurate manual processes. This bias can affect decision-making processes in environments where machine learning models are used to supplement or replace human decision-making. Some key aspects of automation bias are:
- Over-reliance on Automation: Automation bias often manifests as an over-reliance on automated outputs. Users may assume that the automated system is inherently reliable or infallible, leading to a decreased scrutiny of its recommendations. This can result in errors, especially if the system's outputs are incorrect or unsuitable for the context.
- Dismissal of Contradictory Evidence: When faced with a conflict between an automated decision and contradictory evidence (including human intuition or other data sources), users influenced by automation bias might disregard this evidence in favor of the machine-generated decision. This can escalate particularly in high-stakes environments like healthcare, law enforcement, or financial services, where the consequences of flawed decisions can be significant.
- Dependency: Automation bias can lead to a dependency on automated systems, reducing users' skills over time. As operators become more accustomed to relying on automation for decision-making, their ability to perform tasks without assistance may diminish, potentially making manual intervention less effective when it is needed.
- Feedback Loops: Similar to other biases in machine learning, automation bias can create dangerous feedback loops. If decisions made by an automated system are assumed to be correct and are continually fed back into the system as training data without proper vetting, the system may reinforce its own flawed patterns.
- Complacency: Automation bias is often linked to complacency, where users of automated systems become less vigilant and proactive in monitoring and verifying outputs. This complacency can lead to undetected errors proliferating over time, which might be overlooked until they cause significant harm or become much harder to correct.
Addressing automation bias involves implementing robust checks and balances, such as maintaining a level of human oversight, regularly validating and testing the system against new data, and fostering a culture of skepticism where automated decisions are routinely questioned and validated.
In the semiconductor industry, using machine learning for predictive maintenance or process optimization can also encounter confirmation bias. For instance, suppose a semiconductor manufacturer employs a machine learning model to predict machine failures based on sensor data and operational parameters. The model is trained with historical data predominantly from one highly automated and high-volume production line. The model could develop a bias where it effectively predicts failures for the specific type of machines and operational conditions similar to those of the high-volume line but performs poorly on other lines or with different types of equipment. If the model's predictions are primarily confirmed and reinforced by data from this single production line, it might fail to accurately predict or even recognize failure patterns that are less common or slightly different from those it has been trained on. If the data shows that temperature spikes above a certain threshold have previously led to machine failures on the high-volume line, the model might overly focus on this specific condition as a predictor of failure. Consequently, the model could ignore or underweight other critical factors like vibration levels, humidity, or chemical exposure that might be more relevant predictors in other contexts or on other lines. This confirmation bias can lead the maintenance team to concentrate only on temperature controls, potentially overlooking other deteriorating conditions that could lead to unexpected failures.
Bias can appear at multiple stages of a machine learning project, impacting the overall fairness and performance of the system:
- Access to Machine Learning Programs: Bias can arise in who has access to develop or use machine learning technology. This can be due to economic, educational, or geographic factors that limit the diversity of people who can contribute to and benefit from AI.
- Data Collection and Preparation: This stage is critical as biases in data can lead to biases in model outcomes. If the data is not representative of all groups or contains historical biases, the model will likely perpetuate or even amplify these biases.
- Training the Model: The choice of algorithms and the methods used for training can also introduce bias. For example, if a model is optimized only for accuracy on the majority class in an imbalanced dataset, it may perform poorly for the minority class.
One example is bias in model equations, e.g. with logistic regression: The logistic regression model predicts the probability that a given input belongs to a particular class. The basic form of logistic regression is:
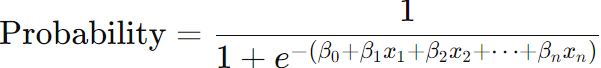 ----------------- [3352a] ----------------- [3352a]
Bias Introduction: If the dataset used to estimate the coefficients
β has historical biases or lacks representation from all groups, the model will learn these biases. For example, if a hiring dataset has fewer examples of successful female candidates due to historical biases, the model might undervalue qualifications typically held by women. Mitigation: To avoid this, we can:
- Resample the dataset to ensure all classes are equally represented.
- Reweight the loss function to give higher importance to underrepresented classes.
- Include fairness constraints during optimization that adjust for disparities in model predictions across groups.5
Another example is bias in decision thresholds, e.g. threshold setting in classification. In binary classification, a common practice is to set a threshold at 0.5 to decide between two classes. However, this might not be fair for all groups.
Bias Introduction: Using a single threshold might lead to higher false positive rates for some groups compared to others if the data distribution varies across groups.
Mitigation:
- Adjust the decision threshold for different groups based on ROC curves or performance metrics that consider both fairness and accuracy.
- Use cost-sensitive learning, where different costs are assigned to misclassifications for different groups, balancing the rates of false positives and negatives.
- Model Evaluation and Validation: Bias can be overlooked if the metrics used to evaluate a model do not adequately consider fairness across different groups. Models need to be validated not just for overall performance but also for equitable performance across different demographics.
Bias can exist in performance metrics, e.g. accuracy versus balanced accuracy:
Using simple accuracy as a performance metric might be misleading in imbalanced datasets. For instance, if one class significantly outnumbers another, a model might appear to perform well by simply predicting the majority class more frequently.
Mitigation of bias:
- Use balanced accuracy, which calculates the average of recall obtained on each class, giving equal weight to the performance on each class.
- Implement other metrics like F1-score, precision-recall curves, or AUC-ROC for a more nuanced evaluation.
- Deployment of the Model: When deploying models, the context in which they are used can also introduce bias. For instance, a model used in one geographic region or demographic may not perform equitably when applied to another.
- Model Monitoring and Updates: After deployment, continuous monitoring is necessary to ensure the model performs fairly over time as new data and changing conditions can lead to shifts in model accuracy and fairness.
To effectively implement these mitigation strategies, it’s crucial to understand the specific sources and types of bias in your dataset and model. Additionally, continuously monitoring the model's performance in production and adjusting strategies as needed is vital to maintaining fairness over time. By addressing bias actively at each step—from data collection through model deployment—you can help ensure your machine learning models perform fairly and ethically.
Determining what constitutes unfairness in machine learning is challenging and requires a holistic approach. This complexity arises from several factors: - Multiple Definitions of Fairness: There are various definitions of fairness in machine learning, and they often conflict with each other. For example, "demographic parity" requires that the decision rates across different groups are equal, while "equal opportunity" requires that true positive rates across groups are the same. Balancing these different notions of fairness can be tricky and depends on the specific context and goals of the application.
- Cultural and Contextual Variability: Notions of fairness can vary widely across different cultures, legal standards, and social contexts. What is considered fair in one situation or region might not be seen as fair in another. This requires understanding the specific societal norms and values of the groups affected by the machine learning application.
- Trade-offs Between Fairness and Performance: There is often a trade-off between increasing fairness and maintaining high performance metrics like accuracy. For example, adjusting a model to ensure fairness might reduce its overall predictive accuracy. Deciding on the acceptable balance between these aspects involves ethical considerations and stakeholder engagement.
- Dynamic Nature of Fairness: Definitions of fairness may evolve over time as societal norms and regulations change. This makes it necessary to continuously review and update the fairness measures implemented in machine learning systems.
- Stakeholder Involvement: Determining fairness requires input from a diverse set of stakeholders, including domain experts, potentially affected groups, ethicists, and policymakers. This broad involvement ensures that multiple perspectives are considered and that the implemented fairness measures are comprehensive and appropriate.
Given these complexities, a holistic approach is essential for assessing and ensuring fairness in machine learning. This approach should include thorough analysis of the data, consideration of various fairness metrics, continuous monitoring and updating of systems, and engagement with a broad range of stakeholders.
===========================================
|
