=================================================================================
In machine learning, parameters, features, and examples are fundamental concepts that play different roles in the process of building and training models as shown in Table 3866.
Table 3866. Parameters, features and examples in machine learning.
| |
Parameters |
Features |
Examples (or Data Points) |
| Definition |
Parameters are the internal variables or coefficients within a machine learning model that the algorithm learns during the training process. |
Features are the input variables or attributes used to describe each example or data point in a machine learning dataset. |
Examples, also known as data points or instances, are individual entries in a dataset, each characterized by a set of features and associated with a target or label. |
| Symbols and notations |
θ (theta) or W (weight) commonly; subscripts or superscripts, such as W1, b1 (weights and biases in the first layer), for the layers in deep learning and neural networks |
X (uppercase) or x (lowercase)commonly; x1, x2, ..., xn to represent individual feature variables for a dataset |
x (lowercase) with an index or subscript to distinguish between different data points, e.g. x1, x2, ..., xm represent individual examples in a dataset. x (lowercase) with an index or subscript to distinguish between different data points. For example, x1, x2, ..., xm represent individual examples in a dataset. |
| Linear regression |
θ0 (intercept), θ1 (weight for feature x1) |
X (matrix of feature values), x1 (individual feature) |
x1, x2, x3 (individual data points), y1, y2, y3 (target values) |
y = θ0 + θ1 * x1 (Here, θ0 represents the intercept parameter, θ1 represents the weight parameter for the feature x1, x1 is a feature value from a specific example, and y is the predicted output.) |
| Role |
Parameters capture the relationships and patterns in the data. They are used to make predictions or classifications based on the features provided. |
Features provide the information that the machine learning model uses to make predictions or classifications. The quality and relevance of features significantly affect model performance. |
Examples are used for both training and testing machine learning models. During training, examples help the model learn relationships between features and targets. During testing, new examples are used to evaluate the model's performance. |
| Learning |
Machine learning algorithms adjust the parameters during the training process to minimize a loss function, which measures the error between model predictions and actual target values. |
Feature engineering and preprocessing involve preparing and optimizing the features to make them suitable for the model. This can include techniques like scaling, encoding, and transformation. |
Examples are used to train the model by providing input features and corresponding target values. The model learns patterns and relationships from these examples. |
| Quantity |
The number of parameters depends on the model's architecture and complexity. More complex models often have a larger number of parameters, such as deep neural networks with millions of weights. |
The number of features is determined by the dataset. Each data point (example) has a set of features, and the total number of features remains constant across all examples in the dataset. |
The number of examples depends on the size of the dataset. A larger dataset typically contains more examples, which can lead to better model generalization if it is diverse and representative. |
| Examples |
Parameters in a linear regression model include coefficients for each feature, while in a neural network, parameters encompass weights and biases associated with neurons. |
In a dataset of housing prices, features might include the number of bedrooms, square footage, and location. In text classification, features can be the words or tokens present in a document. |
In a dataset of customer reviews for a product, each review with its associated features (text, rating, sentiment) is an example. In image classification, each image with its pixel values is an example. |
| Dataset |
|
 |
| Overall |
Parameters represent the learned knowledge within a model and are adjusted during training. |
Features describe the characteristics or attributes of data points and influence model predictions. |
Examples are individual data points in a dataset, each consisting of features and a target variable used for model training and evaluation. |
"X" in the Naive Bayes classification and many other machine learning algorithms often represents the feature vector. A feature vector is a numerical representation of the features or attributes of a data point. Each component or element of the feature vector corresponds to a specific feature, and together they provide a concise and structured representation of the data for the algorithm to work with. In Naive Bayes classification for text, word frequencies, presence or absence of specific words, and other relevant properties of the text are used to create feature vectors. These feature vectors are numerical representations of the text data that the Naive Bayes algorithm uses for classification. This approach represents the document as a binary feature vector. Each element in the vector corresponds to the presence (1) or absence (0) of a particular word in the document:
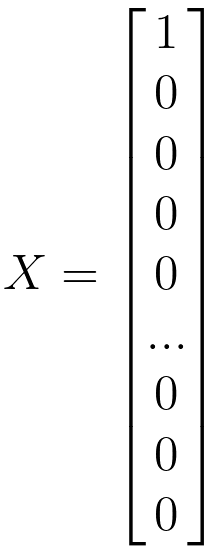 ------------------------------------------------------- [3866a] ------------------------------------------------------- [3866a]
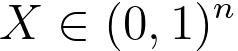 ------------------------------------------------------- [3866b] ------------------------------------------------------- [3866b]
Each element in this vector in Equation 4026c represents the value of a specific feature. For instance, word Xi indicates {word i appears in an document}. There are 2n possible vectors of Xi, there are then 2n parameters.
It is important to mention that the reason of underfitting with a model is normally the model has too few parameters or features. For example, a linear model trying to fit highly nonlinear data. On the other hand, the reason of overfitting with a model is normally the model has too many parameters or features. For example, a very high-degree polynomial model trying to fit a small dataset.
============================================
|
