Input data (sample and feature) (multiple and single sample/example) - Python for Integrated Circuits - - An Online Book - |
||||||||||||||||||||||||||||||||||||||||||||||
| Python for Integrated Circuits http://www.globalsino.com/ICs/ | ||||||||||||||||||||||||||||||||||||||||||||||
| Chapter/Index: Introduction | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | Appendix | ||||||||||||||||||||||||||||||||||||||||||||||
================================================================================= Figure 3907a shows how supervised learning works. To provide a precise characterization of the supervised learning problem, the objective is to acquire a function h: X → Y from a given training set. This function, denoted as h(x), should excel at predicting the associated value y. Traditionally, this function h is referred to as a "hypothesis" due to historical conventions.
Figure 3907a. Workflow of supervised learning. In machine learning, a training example is typically represented as a pair of input features () and their corresponding target variable (). This pair, denoted as , is called a training example because it is used during the training phase of a machine learning algorithm to teach the model how to make predictions or learn patterns from data. Here's why is called a training example:
When you have multiple training samples (also known as a dataset with multiple data points), the equations for the hypothesis and the cost function change to accommodate the entire dataset. This is often referred to as "batch" gradient descent, where you update the model parameters using the average of the gradients computed across all training samples.
Figure 3907b. Multiple training samples, features, and outputs in csv format. Table 3907a lists some examples of features corresponding veriables of some regression models. Table 3907a. Examples of features corresponding veriables of some regression models.
In Figure 3907b, pair is the ith training example. On the other hand, n is used as a notation of how many features in the training process. Whether the hypothesis obtained from a machine learning process is a random variable or not depends on various factors, and it's not only determined by whether the input data is a random variable. Table 3907ab list the randomness of hypothesis depending on learning algorithms and input data in the learning process of "data > learning algorithm > hypothesis". Table 3907ab. Randomness of hypothesis depending on learning algorithms and input data.
Hypothesis (for multiple training samples): The hypothesis for linear regression with multiple training samples is represented as a matrix multiplication. Let be the number of training samples, be the number of features, be the feature matrix, and be the target values. The hypothesis can be expressed as: where,
In machine learning, hypothesis representation is a fundamental concept, especially in supervised learning tasks like regression and classification. The hypothesis is essentially the model's way of making predictions or approximating the relationship between input data and the target variable. It is typically represented as a mathematical function or a set of parameters that map input features to output predictions. In linear regression, the hypothesis represents a linear relationship between input features and the target variable. The hypothesis function is defined as: Here,
The goal of linear regression is to find the values of that minimize the difference between the predictions and the actual target values in the training data. For multinomial Naive Bayes algorithm, we have, where,:
For instance, for house prices depending on the house size, we have the table below, Table 4026b. House prices depending on the house size.
xj in Table 4026b are considered as features. Features are also known as independent variables or predictors, and they are the input variables used to make predictions or estimate an outcome, which in this case is house prices. In matrix linear algebra notation for the cases of multiple examples, you can represent the derivative of a scalar function J(θ) with respect to a vector θ as the gradient, which is a vector itself. The gradient is denoted as ∇J(θ) and is defined as a vector of partial derivatives of J(θ) with respect to each element of θ. Let θ be an (n+1)-dimensional column vector: And J(θ) is a scalar function, then the gradient ∇J(θ) with respect to θ would be an (n+1)-dimensional column vector: Each element of ∇J(θ) represents the rate of change of J(θ) with respect to the corresponding element of θ. In this case, there are n+1 terms in the gradient vector because θ is an (n+1)-dimensional vector, including the bias term θ₀. If n = 2, then, the gradient ∇J(θ) with respect to θ would be a 3-dimensional column vector: These three terms represent the rate of change of J(θ) with respect to each of the three elements of θ: θ₀, θ₁, and θ₂. The specific values of ∂J/∂θ₀, ∂J/∂θ₁, and ∂J/∂θ₂ would depend on the function J(θ) and would need to be computed based on the function's mathematical expression. If A is 2 x 2 matrix, then A can be given by: In some cases, e.g. used as a regularization term, we have: function: f(A) = A₁₁ + (A₁₂)² ------------------------ [3907g] Since: Therefore, the derivative of f(A) with respect to the elements of the matrix A is: Here, each element of this matrix represents the rate of change of f(A) with respect to the corresponding element of A. The derivative (gradient) of the function f(θ) = θ₁₁ + (θ₁₂)² with respect to θ, and the function itself can be plotted by the python script as shown in Figure 3907c.
(a)
(b)
In global optimization, we set: In this sense, this is a n easy way to compute the derivative of J(θ) with respect to θ. The cost function in linear regression is typically represented using the mean squared error (MSE) for multiple training samples. The cost function is defined as: where,
We have the capital X called the design matrix. , Then, θ is a vector, so that we have, For y vector, it stacks up into a big column vector, Then, J(θ) can be given by, Combining Equations 3907s and 3907t, then we can have, We know, Therefore, Then, we have, Then, we have, Therefore, we can get "Normal Equation" given by, where,
The Normal Equation is a mathematical formula used in linear regression to find the coefficients (parameters) of a linear model that best fits a given set of data points. Linear regression is a statistical method used to model the relationship between a dependent variable (the target or output) and one or more independent variables (predictors or features) by fitting a linear equation to the observed data. By solving the Normal Equation, we can obtain the values of the coefficients θ that minimize the sum of squared differences between the predicted values of the dependent variable and the actual observed values. These coefficients define the best-fitting linear model for the given data. While the Normal Equation provides a closed-form solution for linear regression, there are also iterative optimization methods like gradient descent that can be used to find the coefficients, especially when dealing with more complex models or large datasets. Nonetheless, the Normal Equation is a valuable tool for understanding the fundamental principles of linear regression and for solving simple linear regression problems analytically. When you use the Normal Equation to solve for the coefficients (θ) in linear regression, you are essentially finding the values of θ that correspond to the global minimum of the cost function in a single step. In linear regression, the goal is to find the values of θ that minimize a cost function, often represented as J(θ). This cost function measures the error or the difference between the predicted values (obtained using the linear model with θ) and the actual observed values in your dataset. For SVM, we can transform (θ0, θ1, ..., θn) into (b, w1, ..., wn): To find the values of θ that minimize this cost function, you can use the Normal Equation, which provides an analytical solution. When you solve the Normal Equation, you find the exact values of θ that minimize J(θ) by setting the gradient of J(θ) with respect to θ equal to zero. The key point is that this solution is obtained directly, without the need for iterative optimization algorithms like gradient descent. Gradient descent, for example, iteratively adjusts the parameters θ to minimize the cost function, which may take many steps to converge to the global minimum. In contrast, the Normal Equation provides a closed-form solution that directly computes the optimal θ values in a single step by finding the point where the gradient is zero. However, note that the Normal Equation has some limitations:
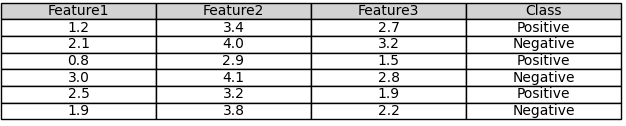
One example of feature illustration is that, in binary classification (e.g. Table 3907b), you have two classes, typically denoted as "positive" (P) and "negative" (N). Given a set of features (X), you want to determine the probability that an observation belongs to the positive class. The probability of an observation belonging to the positive class, given the features, is calculated using Bayes' theorem as follows: Where:
Table 4026c. Binary classification.
On the other hand, bias-variance trade-off is also a crucial concept in machine learning. If you increase the complexity of a model (e.g., by adding more features or using a more complex algorithm), you reduce bias but increase variance, and vice versa. ============================================
|
||||||||||||||||||||||||||||||||||||||||||||||
| ================================================================================= | ||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||


 --------------------------------------- [3907ba]
--------------------------------------- [3907ba]  ------------------------------ [3907c]
------------------------------ [3907c]  ------------------------------ [3907d]
------------------------------ [3907d]  ------------------------------ [3907e]
------------------------------ [3907e]  ------------------------------ [3907f]
------------------------------ [3907f]  ------------------------ [3907l]
------------------------ [3907l]

 ------------------------ [3907m]
------------------------ [3907m] is the hypothesis.
is the hypothesis.  ----------------------------- [3907o]
----------------------------- [3907o]  ----------------------------- [3907p]
----------------------------- [3907p]  ----------------------------- [3907q]
----------------------------- [3907q]  ------------------------ [3907s]
------------------------ [3907s]  ------------------------------------------------------------ [3907t]
------------------------------------------------------------ [3907t]  ---------------------------------------------- [3907u]
---------------------------------------------- [3907u]  ------------------------------------------------------------ [3907v]
------------------------------------------------------------ [3907v]  ------------------------------------------------------------ [3907w]
------------------------------------------------------------ [3907w]  ---------------------------------------------------------- [3907x]
---------------------------------------------------------- [3907x]  ----------------------------------------- [3907y]
----------------------------------------- [3907y]  ----------------------------------- [3907z]
----------------------------------- [3907z]  ----------------------------------- [3907za]
----------------------------------- [3907za]  ----------------------------------- [3907zb]
----------------------------------- [3907zb]  ----------------------------------- [3907zc]
----------------------------------- [3907zc]  ------------------- [3907zd]
------------------- [3907zd] 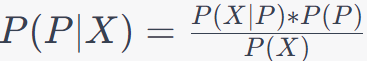 ------------------------------------------ [3907ze]
------------------------------------------ [3907ze]