=================================================================================
Propagation equations in machine learning often refer to the forward and backward propagation equations used in neural networks, which are a type of machine learning model:
i) Forward propagation in neural networks is the phase where input data is fed into the neural network, and the activations are calculated layer by layer until the output is obtained. It typically refers to the process of computing the output of the network given a set of input data.
ii) In the backward propagation phase, the network adjusts its weights based on the calculated error during forward propagation. This is done through the process of backpropagating the error and updating the weights using optimization algorithms like gradient descent.
As discussed in the dog identification in deep learning and neural network, with softmax function, then we can have softmax multi-class network below,
| |
|
|
|
Assuming: , ,  , ,  |
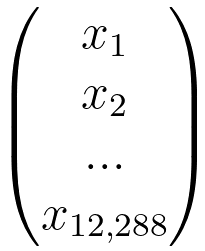
There are also 12,289 x 3 parameters in this problem (3 of (12,288 weights and 1 bias)). Note that the number of the parameters depends on the size of the image.
The shapes of the parameters are: z[1] is (3,1), w[1] is (3, n), x is (n, 1), a[1] and b[1] is (3, 1), z[2] and b[2] is (2, 1) because there are 2 neurons in the second layer, w[2] is (2, 3), a[2] is (2, 1), z[3] and a[3] is (1, 1), w[3] is (1, 2) and b[3] is (1, 1). These numbers are very helpful, especially when coding. |
| |
|
|
|
Neuron: dog, horse and sheep |
 |
|
 |
 |
|
|
 |
→ |
dog |

|
| = |
z1(i) |
→ |
| |
|
 |
→ |
horse |

|
z2(i) |
→ |
| |
|
 |
→ |
Sheep |

|
z3(i) |
→ |
| |
|
|
|
Input 1 = a1(1), Output 1 = a1(3), and so on. All the blue circles represent neurons. |
|
= |
|
|
 |
→ |
y^ |
For the case described above and general models, we have,
-
Forward Propagation:

- Input Layer: z[1] = w[1]x + b[1] (where x is the input data)
with matrix: (3, 1) = (3, n) (n, 1) + (3, 1)
Activation Function: a[1] = σ(z[1])
with matrix: (3, 1) = (3, 1)
- Hidden Layers (second neuron): z[2] = w[2]a[1] + b[2]
with matrix: (2, 1) = (2, 3) (3, 1) + (2, 1)
General expression for hidden layers: z[l] = w[l]a[l-1] + b[l]
Activation Function: a[2] = σ(z[2])
with matrix: (2, 1) = (2, 1)
General expression: a[l] = g[l](z[l]) (where g[l]is the activation function in layer l)
- Output Layer: z[3] = w[3]a[2] + b[3]
with matrix: (1, 1) = (1, 2) (2, 1) + (1, 1)
Activation Function: a[3] = σ(z[3])
with matrix: (1, 1) = (1, 1)
General expression: a[L] = σ(z[L]) (where σ is the activation function in the output layer)
y^ = a[3] (where, y^ represents the predicted values)
with matrix: (1, 1) = (1, 1)
- Backward Propagation:
- Output Layer: dz[L] = a[L] − y (where y is the true label)
- Hidden Layers: dz[l] = w[l+1]Tdz[l+1] * g'[l] (z'[l]) (where g'[l] is the derivative of the activation function in layer l)
- Gradients:
 (where J is cost function) (where J is cost function)  - For cases where we have ρ = 3, then we have,
As indicated by the arrows above, in the computation of the partial derivatives, training neural networks commonly follows the process of backpropagation. The backpropagation is an optimization algorithm that computes the gradient of the loss function with respect to the weights of the network. The key idea is to propagate the error backward through the network, updating the weights to minimize the loss. The reason for starting with the last layer and moving backward is tied to the chain rule of calculus. The chain rule allows us to decompose the derivative of a composite function into the product of the derivatives of its individual functions. In a neural network, the error at the output layer depends on the output of the last layer, which in turn depends on the output of the previous layer, and so on.
Starting from the output layer and moving backward through the layers allows us to apply the chain rule in a sequential and efficient manner. We want to compute derivative of the cost with respect to w[3] is because the relationship between w[3] and the cost is easier than the relationship between w[1] and the cost, since w[1] has much more connection going through the network before ending up in the cost computation. In other words, the reason it might be easier to compute the derivative for w[3] compared to w[1] is related to the network architecture. The weights closer to the output layer (e.g., w[3]) are often more directly linked to the final prediction, while weights deeper in the network (e.g., w[1]) may have their effects spread across many layers, making the computation more complex.
- dw[l] = (1/m)dz[l]a[l-1]T
- db[l] = (1/m)∑(i=1 → m) dz[l]i
- da[l-1] = w[l]Tz[l]
These equations represent the flow of information through the neural network during both the forward and backward passes. The forward propagation computes the predicted output, and the backward propagation computes the gradients of the loss with respect to the parameters, allowing the model to update its weights and biases during the training process using optimization algorithms like gradient descent.
There is generally only one forward propagation pass during the inference or prediction phase. However, during the training phase, there are variations in how forward propagation is performed, mainly based on the handling of batches of data. The main types of forward propagation are:
-
Single Input Forward Propagation:
- In this approach, a single input is passed through the network, and the output is computed. This is typical during the inference phase when making predictions on individual data points.
- Batch Forward Propagation:
- Batch forward propagation involves processing multiple inputs simultaneously. A batch of input data is fed through the network, and the outputs are computed in parallel for all the inputs in the batch. This is commonly used during the training phase to improve computational efficiency.
- The use of batch forward propagation in neural network training often involves vectorization. When training a neural network, processing inputs in batches allows us to take advantage of vectorized operations, which can speed up the forward propagation process. Instead of computing the forward pass for each input individually, the computations are performed simultaneously for the entire batch of inputs.
- Mini-Batch Forward Propagation:
- Mini-batch forward propagation is a specific case of batch forward propagation where the entire dataset is divided into smaller batches. Each mini-batch is processed through the network, and the weights are updated based on the average or cumulative gradient computed over the mini-batch. Mini-batch training is widely used in practice and strikes a balance between the efficiency of batch processing and the stochastic nature of processing one data point at a time.
Figure 3727 shows the comparison between batch forward propagation and single input forward propagation.

Figure 3727. Batch forward propagation versus single input forward propagation (code).
To obtain ∂L[i]/∂w[3], we'll use the chain rule and,
 --------------------------------------- [3727b] --------------------------------------- [3727b]
Similar to the discussion above, assuming we have predicted value (ŷ),
 --------------------------------------- [3727ba] --------------------------------------- [3727ba]
 --------------------------------------- [3727bab] --------------------------------------- [3727bab]
And, we have loss function,
 --------------------- [3727bb] --------------------- [3727bb]
We can compute the necessary derivatives,
 --------------------- [3727bc] --------------------- [3727bc]
 --------------------- [3727bd] --------------------- [3727bd]
 --------------------- [3727be] --------------------- [3727be]
Now, applying the chain rule,
 --------------------- [3727bf] --------------------- [3727bf]
Substitute the expressions we derived,
 ------ [3727bg] ------ [3727bg]
Substitute Eqation 3727bab into Equation 3727bg, then we have,
 ------ [3727bh] ------ [3727bh]
Now, simplify further by canceling terms,
 ------ [3727bi] ------ [3727bi]
 ------ [3727bj] ------ [3727bj]
 ------ [3727bk] ------ [3727bk]
 ------ [3727bl] ------ [3727bl]
Therefore, we can get,
 ------ [3727bm] ------ [3727bm]
Then, the cost function can be given by,
 ------ [3727bn] ------ [3727bn]
Now, let's calculate ∂L[i]/∂w[2], which is the partial derivative of the loss L[i] with respect to w[2].
we have,
  ---------------------- [3727bo] ---------------------- [3727bo]
The chain rule is applied similarly as before,
 ---------------------- [3727bp] ---------------------- [3727bp]
Now, let's calculate each part,
 ---------------------- [3727bq] ---------------------- [3727bq]
 ---------------------- [3727br] ---------------------- [3727br]
 ---------------------- [3727bs] ---------------------- [3727bs]
 ---------------------- [3727bt] ---------------------- [3727bt]
Then, we have,
 -------------------- [3727bu] -------------------- [3727bu]
 -------------------- [3727bv] -------------------- [3727bv]
Then, finally we can have,
 -------------------- [3727bw] -------------------- [3727bw]
Then, the cost function (updating formula) is given by,
 -------------------- [3727bx] -------------------- [3727bx]
It is important to mention that caching is useful here since some parameters, which have been computed, e.g. in forward propagation process, will be needed later, e.g. in backward propagation process.
============================================
|









