
Chapter/Index: Introduction | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T | U | V | W | X | Y | Z | Appendix
| Deep learning (DL) is a subfield of machine learning that focuses on the development and training of artificial neural networks to perform tasks without explicit programming. It is inspired by the structure and function of the human brain, consisting of interconnected nodes, or artificial neurons, organized into layers. These neural networks can learn to recognize patterns, make decisions, and perform various tasks through training on large datasets. DL is extremely data-hungry [2, 3] so that DL demands an extensively large amount of data to achieve a well-behaved performance model, i.e. as the data increases, an extra well-behaved performance model can be achieved as shown in Figure 4324a.
Figure 4324a. performance of DL regarding the amount of data. [4] The term "deep" in deep learning refers to the use of deep neural networks, which have multiple layers (hidden layers) between the input and output layers. Each layer in the network extracts features from the input data, and as information passes through these layers, the network can learn hierarchical representations of the data. Deep learning has been particularly successful in tasks such as image and speech recognition, natural language processing, and playing games. The main components of deep learning are:
In the early days, doing deep learning required significant C++ and CUDA expertise, which few people possessed. Nowadays, thank Google for backing the Keras project since it has been fantastic to see Keras adopted as TensorFlow’s high-level API. A smooth integration between Keras and TensorFlow greatly benefits both TensorFlow users and Keras users and makes deep learning accessible to most. Therefore, basic Python scripting skills suffice to do advanced deep-learning research. This has been driven most notably by the development of Theano and then TensorFlow and by the rise of user-friendly libraries such as Keras, which makes deep learning as easy as manipulating LEGO bricks. The two symbolic tensor-manipulation frameworks, namely Theano and then TensorFlow, for Python support autodifferentiation, greatly simplifying the implementation of new models. After its release in early 2015, Keras quickly became the go-to deep-learning solution for large numbers of new startups, graduate students, and researchers pivoting into the field. Some of the primary platforms for deep learning
today are Summarized below: As discussed in support-vector machines (SVM), we have, where, g is the activation function. n is the number of input features. Equation 4324a is a basic representation of a single-layer neural network, also known as a perceptron or logistic regression model, depending on the choice of the activation function g. From Equation 4324a, we can derive different forms or variations by changing the activation function, the number of layers, or the architecture of the neural network as shown in Table 4324a. Table 4324a. Different forms or variations of Equation 4324a.
The Keras handles the problem in a modular way as shown in Figure 4325a.
Figure 4325a. The deep-learning software and hardware stack in Keras process. [1]
K-Folds for cross-validation is rarely used in deep learning. Deep learning models often require a large amount of data to train effectively. In most cases, the available dataset may be so large that splitting it into K-Folds for cross-validation becomes computationally expensive and time-consuming. In such cases, researchers might opt for other techniques like hold-out validation or stratified sampling. Deep learning works because datasets are large, but the compute required keeps increasing. Deep learning has found applications in a wide range of fields due to its ability to automatically learn hierarchical representations from large amounts of data:
Deep learning models, especially deep neural networks, often involve a large number of parameters and complex computations. Training these models can be computationally intensive, and as a result, it can take a significant amount of time to converge to a solution on traditional central processing units (CPUs). Additionally, there are frameworks and libraries, such as TensorFlow and PyTorch, that are optimized to work efficiently with GPUs, making it easier for developers to leverage the computational power of these devices. In recent years, there has also been a growing trend toward using specialized hardware like Tensor Processing Units (TPUs) and other accelerators designed specifically for deep learning tasks, further emphasizing the need for specialized hardware to handle the computational demands of deep learning. Assuming we want to identify whether or not an image is a dog, then we can have a model as shown below:
To train the model, we need images and labels which are labeled as dogs or not dogs. And,, we will train the model with the steps below: i) Initialize the parameters w, b. Here, w is weights and b is bias. ii) Find the optimal w and b. Finding the w and b means to minimize the loss function (see cross-entropy loss function).
iii) Use the found w and b to predict. Now, if we need to identify the animal is a dog, horse or sheep, then we will have the network below:
These equations represent the output of the first neuron in a layer with a sigmoid activation function. The sigmoid function () squashes its input to the range [0, 1], and it's commonly used for binary classification problems. To train the model described above, we need images and labels which are labeled as dogs or not dogs, namely (1, 0, 0). Here, the two 0's are horses and sheeps. Note that in this deep learning network, it is not necessary that the input image has only a dog, but also can have both dog and sheep, or other combinations of the animals. With softmax function, then we can have softmax multi-class network below,
In this case, the division by the sum ensures that the resulting values form a valid probability distribution. The goal with the softmax function is to convert these logits into probabilities that sum to 1. Therefore, the probabilities of the three animals depend on each other. The softmax function is commonly applied to the output of the third neuron in a neural network layer, and is often used in classification problems to convert a vector of raw scores (logits) into probabilities. In this case above, its loss function, which is different from Equaiton 4324b, is given by, where,
The binary cross-entropy loss can be extended to a multi-class setting, e.g. for three classes here. Once the function in Equation 4324e is trained, then the three neurons are trained. In this case, if this animal is not a horse, then the training will push out the horse class out. The loss function used in softmax regression is called cross-entropy loss or log-likelihood loss, where,:
This loss function is specifically designed for classification problems and is different from the mean squared error loss commonly used in traditional regression. The cross-entropy loss penalizes the model more when it makes confident incorrect predictions, which is a suitable characteristic for classification tasks. Additionally, the derivative of the cross-entropy loss with respect to the model parameters is different from the derivative of the mean squared error loss. This is because the softmax activation function and the nature of the output in softmax regression introduce non-linearity and require a different approach in computing gradients during the backpropagation process. For the next step of the deep learning process, if we want to predict the age of a dog, we then need to consider the nature of the data. Since we are dealing with a regression problem when predicting a continuous variable like age, then the formula with the sigmoid activation is not suitable because it's typically used for binary classification. For regression problems, we usually use a linear activation function in the output layer. The predicted age () would be the output of the network without any activation function applied to it: where, is the weight for the single neuron in the output layer. is the bias for the single neuron in the output layer. We train the network to adjust these parameters to minimize the difference between the predicted age and the actual age of the dog. Sigmoid, hyperbolic tangent (tanh), and rectified linear unit (ReLU) loss functions can be used to fit the regression problem in such artificial neural networks. However, if we have categorical age ranges, we might still use the softmax function for classification, but the number of neurons in the output layer and the activation function would depend on the specifics of the problem.
============================================
[1] François Chollet, Deep Learning with Python, 2018. [2] Karimi H, Derr T, Tang J. Characterizing the decision boundary of deep neural networks; 2019. arXiv preprint arXiv: 1912.11460. [3] Li Y, Ding L, Gao X. On the decision boundary of deep neural networks; 2018. arXiv preprint arXiv:1808.05385. [4] Laith Alzubaidi, Jinglan Zhang, Amjad J. Humaidi, Ayad Al‐Dujaili, Ye Duan, Omran Al‐Shamma, J. Santamaría, Mohammed A. Fadhel, Muthana Al‐Amidie and Laith Farhan, Review of deep learning: concepts, CNN architectures, challenges, applications, future directions, Journal of Big Data, 8:53, https://doi.org/10.1186/s40537-021-00444-8, (2021).
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

 --------------------------------- [4324a]
--------------------------------- [4324a]  , which is the formula for linear regression.
, which is the formula for linear regression.


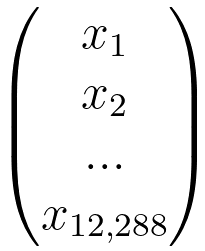


 -------------------------- [4324c]
-------------------------- [4324c]  -------------------------- [4324d]
-------------------------- [4324d] 







 -------------------------- [4324e]
-------------------------- [4324e]  -------------------------- [4324f]
-------------------------- [4324f]