=================================================================================
The cost function in linear regression is typically represented using the mean squared error (MSE) for multiple training samples. The cost function J(θ) is defined as:
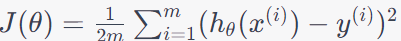 ------------------------------ [3901a] ------------------------------ [3901a]
where,
- m is the number of training samples.
- hθ(x(i)) is the hypothesis's prediction for the i-th training sample.
- y(i) is the actual target value for the i-th training sample.
Then, we can have,
 ---------------------------- [3901b] ---------------------------- [3901b]
The general update rule for θj using the gradient of the loss function is as follows:
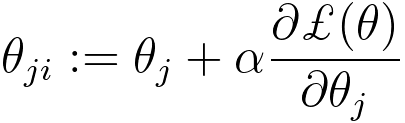 -------------------------------------------- [3901c] -------------------------------------------- [3901c]
Where:
- θj is the current (old) value of the parameter θj.
- θji is the updated (new) value of the parameter θj.
- α is the learning rate, which is a hyperparameter that controls the step size of the update. It is typically a small positive value.
- ∂ℒ(θ) /∂θj is the partial derivative of the loss function ℒ(θ) with respect to θj. This represents the slope of the loss function with respect to the parameter θj.
The second portions in Equations 3901b and 3901c are equal.
Equation 3901a gives you to train the entire set m, so sometimes this type of gradient descent has another name, which is Batch Gradient Descent, which is a variation of the gradient descent optimization algorithm commonly used in machine learning and deep learning. In this case, you think all examples as one batch of data, and then you process all data as a batch. It's one of the simplest forms of gradient descent and is sometimes referred to as "vanilla" gradient descent:
-
Batch Processing: In Batch Gradient Descent, the entire training dataset is used in each iteration to compute the gradient of the cost function with respect to the model parameters. This means that all the training examples are processed together in a single batch to update the model parameters.
-
Gradient Computation: During each iteration, the algorithm computes the gradient of the cost function, which represents the direction and magnitude of the steepest increase in the cost. This gradient is calculated by taking the average gradient of the individual data points in the training batch.
-
Parameter Update: Once the gradient is computed, the model parameters (weights and biases) are updated in the opposite direction of the gradient to minimize the cost function. The size of the step taken in the opposite direction is controlled by a parameter called the learning rate.
Here are some key characteristics of Batch Gradient Descent:
-
Stable Convergence: Batch Gradient Descent tends to converge to a minimum of the cost function in a stable and deterministic manner because it uses the entire dataset in each iteration.
-
High Memory Usage: It requires holding the entire training dataset in memory, which can be computationally expensive if the dataset is large.
-
Slower Updates: Since it computes the gradient using the entire dataset, it can be slower to update the model parameters compared to other variants of gradient descent.
-
Not Suitable for Large Datasets: Batch Gradient Descent is typically not suitable for very large datasets because of its high memory requirements. It also doesn't take advantage of parallelism, making it less efficient for distributed computing. That is, in order to get one update of your parameters (a single step of gradient descent), you need to calculate the some of m examples (e.g. maybe millions of dataset or a couple of Tb dataset).
Despite its limitations, Batch Gradient Descent is often used as a baseline optimization algorithm and for small to moderately sized datasets where memory and computational resources are not significant concerns. Variants like Mini-Batch Gradient Descent and Stochastic Gradient Descent are commonly used when dealing with larger datasets or when faster convergence is desired.
As shown in Table 3901, batch gradient descent can also be used for training SVMs, particularly for solving the soft-margin SVM optimization problem. However, note that SVMs are often trained using optimization algorithms that are specifically designed for their objective function, such as the Sequential Minimal Optimization (SMO) algorithm and the gradient descent-like Pegasos algorithm. These specialized methods can be more efficient than using standard batch gradient descent for SVM training. Batch gradient descent can be applied to SVM training in the manner below:
-
Objective Function: In the soft-margin SVM, you typically minimize an objective function that combines a margin term (maximizing the margin between classes) and a regularization term (penalizing the magnitude of the weight vector). The objective function is often a convex quadratic function.
-
Gradient Descent: Batch gradient descent involves computing the gradient of the objective function with respect to the weight vector over the entire training dataset. The gradient points in the direction of the steepest increase in the function. To minimize the function, you update the weight vector in the opposite direction of the gradient.
-
Regularization Parameter: The regularization parameter, often denoted as C, controls the trade-off between maximizing the margin and minimizing the classification error. A higher C value emphasizes classifying training examples correctly, which may lead to a smaller margin, while a lower C value prioritizes a larger margin, possibly at the cost of misclassifying a few examples.
-
Learning Rate: Choosing an appropriate learning rate is essential. If the learning rate is too large, you might overshoot the optimal solution, and if it's too small, convergence may be very slow.
-
Batch Updates: In batch gradient descent, you update the weight vector using the average gradient computed over the entire training dataset in each iteration.
-
Convergence: The algorithm continues to update the weight vector until a convergence criterion is met, which could be a maximum number of iterations or until the change in the weight vector becomes small.
Table 3901. Applications and related concepts of batch gradient descent.
============================================
|